Resumen
Las “ómicas” son las ciencias que permiten estudiar un gran número de moléculas, implicadas en el funcionamiento de un organismo. En las últimas décadas, el avance tecnológico ha permitido el estudio a gran escala de muchos genes, proteínas y metabolitos, permitiendo la creación de la genómica, proteómica, metabolómica, entre otras. Cada una de estas áreas ha ayudado a un mejor entendimiento de la causa de ciertas enfermedades. Además, la aplicación del conocimiento sobre las “ómicas” a la clínica podrá utilizarse para hacer un diagnóstico más temprano o para prevenir el desarrollo de una enfermedad. Así, la medicina se podrá convertir en medicina personalizada, donde cada individuo llevará un tratamiento para una determinada enfermedad acorde a su información genética y a su medio ambiente. En este artículo se define a cada una de las “ómicas”, la metodología que se usa para su análisis y un ejemplo de su aplicación clínica.
Palabras clave: ácido desoxirribonucleico (ADN), ácido ribonucleico (ARN), proteínas, metabolitos, ciencias “ómicas”.
The “omics” sciences, how does this help health sciences?
“Omics” are defined as a group of disciplines that aim to collect a large number of biological molecules involved in the function of an organism. In the last decades, technological evolution allowed us to better understand global changes in genes, proteins and metabolites, giving rise to genomics, proteomics, metabolomics, among others. These fields have contributed to the generation of knowledge regarding the cause of diseases. The application of the “omics” to the clinics could help diagnose or prevent certain diseases. In the future, treatment will be specific for each patient according to their genetical background and environment exposure, creating personalized medicine. This article defines every –omic, the technological tools used for its analysis, and examples of its clinical applications.
Keywords: DNA (deoxyribonucleic acid), RNA (ribonucleic acid), proteins, metabolites, “omics” sciences.
Introducción
Historia del ADN
 |
El ADN está formado por la unión de nucleótidos formados por bases nitrogenadas (adenina, guanina, citosina, timina), un azúcar (desoxirribosa) y ácido fosfórico. La combinación de estos nucléotidos da origen a los genes, los cuales guardan la información genética. |
|
|
 |
Toda la información genética que heredamos de nuestros padres se encuentra en el genoma, que está formado por el ácido desoxirribonucleico (ADN) y que se localiza en el núcleo de las células de nuestro organismo. El ADN, que mide aproximadamente dos metros de longitud, se superenrolla para caber en el núcleo que mide seis micras. Para esto, el ADN se ordena en cromosomas, de los cuales el ser humano tiene 22 pares de somáticos y un par de los sexuales (cromosomas X y Y).
En 1944, Oswald Avery, Colin MacLeod y MacLyn McCarty descubrieron que el ADN es el “principio de transformación” o material genético (Avery, MacLeod y McCarty, 1944). Sin embargo, la comunidad científica de aquella época exigía más información sobre dicho material genético, por lo cual, diversos investigadores continuaron en la búsqueda de pruebas y fueron Alfred Hershey y Martha Chase (1952) quienes demostraron definitivamente que el ADN es la molécula que guarda la información genética heredable. Posteriormente, en 1953, Watson y Crick describieron la estructura del ADN, la cual está formada por dos cadenas complementarias que se unen en direcciones inversas (1953). Sin embargo, fue hasta 1977, que se logró decodificar o secuenciar por primera vez el ADN, lo cual quiere decir que se estableció el orden de los nucléotidos de un fragmento de ADN. Esto asentó los fundamentos para el análisis y secuenciación del genoma. Sin embargo, debido al desarrollo científico y tecnológico que se logró en los años siguientes, fue que en 2001 se logró secuenciar el genoma humano (Venter
et al., 2001).
Dogma central de la biología molecular
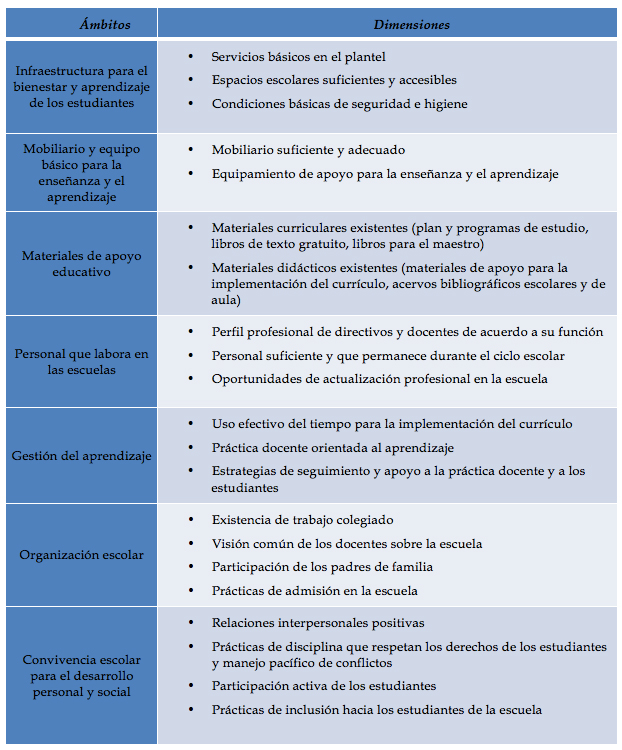
Se conoce como el dogma central de la biología molecular a la forma como fluye la información genética del ADN, desde su paso por el ácido ribonucleico mensajero (ARNm) y hasta llegar a las proteínas.
El ADN está formado por la unión de nucleótidos formados por bases nitrogenadas (adenina, guanina, citosina, timina), un azúcar (desoxirribosa) y ácido fosfórico. La combinación de estos nucléotidos da origen a los genes, los cuales guardan la información genética. A partir de los genes, se lleva a cabo la transcripción, mecanismo por el cual el ADN se convierte a ARNm. Finalmente, la traducción permitirá que el ARNm se convierta en una proteína.
Por lo tanto, se puede decir que el ADN es un archivero en el que se guarda toda la información. El ARNm es el mensajero que lleva la información del archivero a donde se va a utilizar. Finalmente, esa información es utilizada por los obreros, correspondientes a las proteínas (véase figura 1). Cabe mencionar que el ADN se replica para que a partir de una célula madre, se generen dos células hijas conteniendo el mismo material genético.
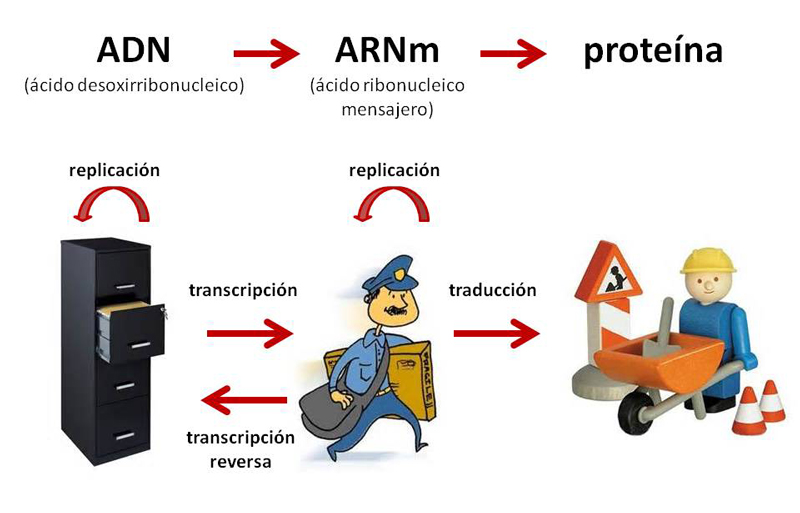 Figura 1.
Figura 1. El ADN es como un archivero que contiene la información que el mensajero distribuye para que se lleve a cabo la síntesis de proteínas (o que actúe el obrero).
Un gen es un fragmento de ADN que contiene la información genética. Las regiones que separan a los diferentes genes se llaman regiones intergénicas. Un gen está conformado por diversas partes como el promotor, exones e intrones, principalmente. El promotor es la secuencia del gen que es reconocida por la maquinaria de transcripción para convertir el ADN a ARNm. Los exones son las secuencias del ADN que dan origen a la proteína. Estos exones pueden estar interrumpidos por los intrones, que son regiones que pueden regular la transcripción de los genes. El ARNm maduro sólo estará formado por la secuencia de los exones, la cual va a ser traducida para sintetizar una proteína (véase figura 2).
 Figura 2.
Figura 2. Los exones se traducen para sintetizar las proteínas.
El ADN se encuentra en todos los núcleos de las células del organismo y es exactamente el mismo, por lo que, se puede extraer ADN de la sangre, cabello, saliva o cualquier célula, obteniendo la misma información genética. Sin embargo, el ARNm es diferente, ya que a partir del ADN que tienen todas las células, se transcribe solamente el ARNm que necesita una célula determinada, para posteriormente ser traducido a la proteína que ejercerá la función en dicha célula. Por lo tanto, el ARNm y las proteínas son dinámicas y son específicas de tiempo, tratamientos y de células.
El ADN del humano está formado por tres billones de nucleótidos que contiene alrededor de 30 000 a 40 000 genes, donde entre 1 y 2% del genoma son regiones codificantes y el resto no codifican para una proteína, pero regulan la presencia del ARNm o expresión de los genes (Harrow
et al., 2012).
“Ómicas”: generalidades de análisis de muchos datos
En los últimos años ha existido un gran avance en el desarrollo de la tecnología, lo cual ha provocado que se generen equipos analíticos que logran identificar y medir muchas moléculas. Esto ha ido de la mano con la creación de grandes computadoras, que permiten el almacenamiento de gran cantidad de información, de igual manera, el desarrollo de
software ayuda al análisis de los datos generados. Todo esto ha dado como resultado el análisis de diferentes moléculas (ADN, ARN, proteínas, etcétera) y la creación de redes de interacción entre ellas para comprender con más exactitud a los sistemas biológicos complejos.
En los años 1980, el término “ómica” se acuñó para referirse al estudio de un conjunto de moléculas. Por ejemplo, genómica se refiere al estudio de muchos genes en el ADN; transcriptómica es el estudio de muchos transcritos o ARNm; proteómica es el estudio de muchas proteínas; metabolómica es el estudio de muchos metabolitos, entre otros.
1
Antes, los químicos y biólogos realizaban la parte experimental de su investigación y análisis de una o pocas moléculas que se podían estudiar en laboratorios. Gracias al avance de la tecnología y de las herramientas de análisis, se incrementó el número de moléculas detectables al mismo tiempo, por lo que se han formado grupos multidisciplinarios constituidos por biólogos, químicos, médicos, programadores, bioinformáticos, bioestadísticos, que juntos colaboran para la interpretación de todos los datos recabados.
Al aumentar el número de moléculas a analizar fue necesario acrecentar también el tamaño de muestra para mantener un poder estadístico válido. Es por esto que se crearon biobancos tales como el de
UK Biobank (biobanco del Reino Unido), para el cual se reclutaron a 500 000 individuos y se tomaron muestras de sangre, orina y saliva para su análisis posterior. Este tipo de biobancos ayudará a las diversas disciplinas “ómicas” en su estudio de las enfermedades para mejorar el diagnóstico, prevención y tratamiento de las mismas.
A continuación, se describe brevemente lo que estudia cada “ómica”, así como la metodología empleada para su análisis y alguna aplicación en la clínica. Es importante hacer notar que los datos que se obtienen de cada una no nos permiten conocer completamente un sistema biológico. Sólo la integración de varias de éstas y la relación que existe entre ellas, nos es útil para conocer globalmente a dichos sistemas.
Genómica
La genómica fue la primera “ómica” en crearse, esta ciencia se encarga del estudio del genoma o ADN. Anteriormente, la tecnología permitía estudiar pocos genes, así como sus cambios o mutaciones, a lo que se le denominaba genética. Sin embargo, la tecnología avanzó y a principios del siglo XXI se reportó la secuencia del genoma humano (Venter
et al., 2001), lo que quiere decir que se descifró el orden de todos los nucleótidos contenidos en el ADN del humano (International Human Genome Sequencing Consortium, 2004). La secuencia del genoma reveló que 99% del genoma entre humanos es el mismo y sólo 1% es diferente. Estas diferencias son llamadas variantes de un solo nucleótido (SNV por sus siglas en inglés), anteriormente llamados polimorfismos de un solo nucleótido o SNP (véase figura 3). Estas variantes son frecuentes y confieren susceptibilidad o protección para desarrollar enfermedades.
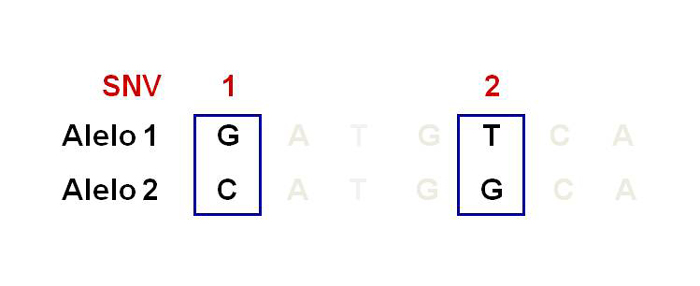 Figura 3.
Figura 3. Polimorfismos de un solo nucleótido.
Anteriormente, se estudiaban fragmentos de ADN y su localización en los diferentes cromosomas por medio de metodologías de hibridación
in situ con fluorescencia (FISH). De esta forma era posible señalar cierto fragmento del ADN, conteniendo uno o varios genes, el cual era el causante de una enfermedad, debido a la depleción, duplicación, inversión y translocación cromosómica de dicho fragmento de ADN. Posteriormente, surgió la secuenciación con el método Sanger que consiste en replicar la región del genoma de interés por medio de cebadores específicos y utiliza dideoxinucleótidos marcados radioactivamente que posteriormente evolucionaron a marcaje fluorescente. Estos nucleótidos marcados al ser incorporados en la nueva cadena amplificada, finalizarían la reacción permitiendo conocer el último nucleótido de dicha reacción y establecer la secuencia del ADN. Esta metodología se desarrolló en los la década de 1970 y se acopló a estrategias de secuenciación a gran escala, lo que permitió realizar la secuenciación del genoma humano en 2001; sin embargo, estas metodologías eran muy costosas.
El avance de la tecnología ha permitido crear nuevos métodos para reducir costos y obtener secuenciaciones masivas, creando la “secuenciación de siguiente generación”, volviendo más accesible su uso. En la actualidad es posible elegir qué regiones del genoma se desean secuenciar. Por ejemplo, a partir del ADN de un individuo se puede secuenciar el genoma completo, solo exones o regiones específicas del genoma (genes), con la finalidad de encontrar la región del genoma que pudiera estar afectada o mutada y ser la posible causante de alguna enfermedad.
Por otra parte, el descubrimiento de las variantes de un solo nucleótido originó que se desarrollaran otras metodologías para su identificación, como la llamada genotipificación. La genotipificación consiste en amplificar el ADN y añadir a la reacción una sonda (fragmento de 25 nucleótidos) que se pueda hibridar o unir a la variante de nuestro interés y así obtener el genotipo del individuo.
|
[…] el término “ómica” se acuñó para referirse al estudio de un conjunto de moléculas. |
|
|
|
La genotipificación se puede realizar para pocas variantes de forma individual o en conjunto. Sin embargo, en la última década la tecnología desarrollada permite analizar hasta dos millones de variantes al mismo tiempo para cada individuo. Esta tecnología generó la creación de los estudios de asociación del genoma completo (
genome wide association studies, GWAS). Estos estudios permiten comparar millones de variantes entre cohortes de casos y controles, resultando en la asociación de algunas variantes con la enfermedad de interés. El gran avance tecnológico, la creación de consorcios de bancos de ADN de miles de muestras de humanos, el apoyo de herramientas estadísticas y la referencia del genoma humano ha permitido descubrir variantes raras o comunes que contribuyen al desarrollo de una enfermedad (Begum
et al., 2012; LaFramboise, 2009; Manolio, 2010). Sin embargo, la función de muchas de esas variantes y de los genes aledaños no se conoce (Gutiérrez
et al., 2011), lo que abre el horizonte para explorar nuevas vías para entender mejor la causa de las enfermedades.
Por otra parte, la genética ha ayudado a describir enfermedades que son heredables con un patrón mendeliano, las cuales generalmente contienen mutaciones (poco frecuentes) en la parte que codifica un gen, provocando que haya un cambio funcional de la proteína y que se presente la enfermedad (por ejemplo, fibrosis quística). Sin embargo, hay enfermedades que no siguen el patrón mendeliano y se les conoce como enfermedades comunes. Es aquí donde la genómica ha permitido describir muchas variantes que están asociadas a alguna enfermedad, por ejemplo: obesidad y diabetes. Las variantes asociadas a enfermedades comunes son frecuentes (a diferencia de las mutaciones) y se presentan en regiones regulatorias de los genes y conceden susceptibilidad o protección para el desarrollo de la enfermedad.
Imagen: kropekk_pl.
Existen algunas limitantes de los estudios genómicos como son las siguientes: primero, las variantes asociadas a una enfermedad explican solamente una pequeña parte del componente heredable; en segundo lugar, las variantes pueden ser reguladas por factores ambientales independientemente de la secuencia del ADN (ver epigenómica). Es por esto que la genómica ofrece correlaciones entre las enfermedades y las variantes génicas, sin demostrar cómo esa variable puede ser causal de la enfermedad. Entonces, es necesario integrar estas correlaciones con otras “ómicas” para encontrar la función de los genes y de las variantes que los modulan, para comprender mejor la causa de la enfermedad.
Transcriptómica
El ADN se transcribe a ARNm y a éste le llamamos también transcrito. La transcriptómica es la “ómica” que se encarga de estudiar la expresión de los transcritos que provienen de diferentes genes. El ARNm es específico de cada célula y de las condiciones fisiopatológicas en determinado momento. Por ejemplo, el ARNm extraído de células del músculo será diferente a las células del hígado antes y después de comer. Es por esto que la transcriptómica se hace en tejido y en tiempo específico, ya que la transcripción es muy dinámica.
Anteriormente, se creía que gran parte del ADN que no se transcribía a ARNm, no tenía ninguna función y se consideraba ADN “basura.” Sin embargo, además del ARNm existen otros transcritos no codificantes como son: 1) los miRNA (micro ARN, secuencias de 21-25 nucleótidos) y, 2) los lncRNA (ARN largos no codificantes, >200). Estos tipos de transcritos no codificantes tienen como función regular la expresión de los ARNm codificantes. Por lo tanto, sabemos en la actualidad que estas regiones del ADN son secuencias reguladoras de la expresión de diversos genes y no son “basura”.
Las metodologías que se utilizan para analizar el ARNm son: 1) microarreglos o 2) secuenciación del ARN (RNAseq por sus siglas en inglés). Los microarreglos consisten en hibridar el ARNm de un determinado tejido a secuencias de genes previamente conocidos que se encuentran unidas a un microarreglo. De esta forma, se pueden hacer comparaciones entre casos o controles o simplemente ver qué genes se expresan mayoritariamente en ciertas condiciones. En cambio, el RNAseq consiste en secuenciar todos los transcritos presentes en esas condiciones, teniendo como consecuencia encontrar nuevos transcritos que no se conocían anteriormente y nuevos genes involucrados en un padecimiento.
En la actualidad, una de las aplicaciones de la transcriptómica es el análisis de la expresión de genes implicados en diferentes tipos de cánceres. Por ejemplo, en México se ha utilizado el microarreglo Oncotype RX, el cual mide la expresión de 21 genes involucrados en el cáncer de mama, para mejorar la toma de decisiones del tratamiento por parte del clínico tratante. Los resultados mostraron que al aislar el ARNm de una biopsia del tumor de mama e hibridándolo al microarreglo aumentó la expectativa de vida de los pacientes y redujo los costos de la enfermedad (Bargalló-Rocha
et al., 2015).
Proteómica
El ARNm es traducido a proteínas (formadas por aminoácidos), las cuales están encargadas de realizar la función correspondiente del gen. La proteómica se encarga de estudiar muchas proteínas presentes en una muestra.
Una vez que las proteínas son traducidas pueden sufrir modificaciones post-traduccionales, tales como cortes, fosforilación, glucosilación, sumolización. Estas modificaciones provocan cambios estructurales que controlan la formación de complejos funcionales proteicos, regulan la actividad de las proteínas y las transforman en formas activas o inactivas. Algunos de estos cambios son señales para la estabilidad o degradación de las proteínas. La proteómica estudia a las proteínas, así como las modificaciones post-transcripcionales que las regulan. Al igual que el ARNm, las proteínas se expresan en tejido y tiempo específico, por lo que la toma de la muestra dependerá del tejido y del estadio de la fase celular de interés.
La metodología para estudiar la proteómica consiste principalmente en: 1) separar las proteínas por técnicas cromatográficas (líquidos, gases, etcétera) o electroforéticas (2D-PAGE); 2) digerir las proteínas; 3) detectar los fragmentos peptídicos (de proteínas) por espectrometría de masas, y 4) identificar las proteínas.
La aplicación de la proteómica a la clínica se encuentra en etapas tempranas; sin embargo, actualmente se utiliza para: a) identificación de proteínas en una muestra biológica; b) identificación de un perfil de proteínas comparando muestras entre casos y controles; c) determinar la interacción entre diversas proteínas y su red funcional, y d) identificar las modificaciones post-transcripcionales (Mishra, 2010). De esta forma, se lograrán encontrar biomarcadores (proteínas) que sirvan para diagnosticar enfermedades, con el fin de dar un tratamiento más adecuado en un futuro.
Imagen: OpenClipart-Vectors.
El gran esfuerzo de muchos científicos ha logrado crear el Proyecto del Proteoma Humano, que proporciona una lista de proteínas que se han encontrado en diferentes tipos celulares y órganos de adultos o de fetos. Estos datos son públicos y reporta más de 30 000 proteínas identificadas en el humano (Omenn
et al., 2015).
El uso de la proteómica lo podemos ver en diferentes enfermedades como son: cáncer, diabetes, obesidad, entre otras. Por ejemplo, dentro del ámbito de la reproducción asistida, la proteómica ha sido de gran interés para analizar los gametos (óvulos y espermatozoides) e identificar proteínas que puedan ser utilizados como biomarcadores para poder seleccionar aquellos gametos que aseguren una mejor fertilización y aumentar la tasa de éxito de la reproducción asistida (Kosteria
et al., 2017).
Metabolómica
Los metabolitos son aquellas moléculas que participan como sustratos, intermediarios o productos en las reacciones químicas del metabolismo. La metabolómica se define como una tecnología para determinar los cambios globales en la concentración de los metabolitos presentes en un fluido, tejido u organismo en respuesta a una variación genética, a un estímulo fisiológico o patológico (Park, Sadanala y Kim, 2015). La metabolómica nos permite analizar el perfil metabólico de una muestra, de forma cuantitativa y cualitativa. La metodología utilizada es la misma que la descrita en proteómica, en la que se pueden encontrar metabolitos específicos relacionados con el desarrollo de una enfermedad o con la respuesta a un tratamiento nutricio o farmacológico.
Recientemente, se ha logrado avanzar de forma importante en el conocimiento de la metabolómica de la obesidad y la diabetes, al asociar la concentración de ciertos metabolitos en suero y orina con un mayor riesgo de desarrollar dichas enfermedades. Estos metabolitos incluyen a varios aminoácidos, lípidos, hidratos de carbono y ácidos nucleicos.
En condiciones de obesidad, la concentración circulante de algunos aminoácidos, especialmente los de cadena ramificada (isoleucina, leucina y valina), está elevada (Chevalier
et al., 2005). En población infantil mexicana se logró asociar un perfil de aminoácidos (mayor concentración de arginina, leucina/isoleucina, fenilalanina, tirosina, valina y prolina) con obesidad, con lo cual se tiene la capacidad de predecir un mayor riesgo de hipertrigliceridemia en los siguientes dos años (Moran-Ramos
et al. 2017).
Por otro lado, la obesidad se caracteriza por la presencia elevada de ácidos grasos libres en suero. De hecho, se ha visto que la concentración de ácido oleico, palmítico, palmitoleico y esteárico es elevada, mientras que la concentración de etanolamina y lisofosfatidiletanolamina se encuentra disminuida en organismos obesos (Moore
et al., 2014). Aunados a los ácidos palmítico, palmitoleico y esteárico, las ceramidas y el diacilglicerol son metabolitos que se encuentran aumentados en pacientes diabéticos (Fiehn
et al., 2010). En lo que se refiere a los hidratos de carbono, se ha observado que los pacientes con obesidad y diabetes tienen concentraciones aumentadas de glucosa, fructosa y glicerol en suero (Fiehn
et al., 2010; Moore
et al., 2014).
|
Anteriormente, se pensaba que el ADN era una estructura simple y lineal. Sin embargo, en las últimas décadas se ha demostrado que el ADN puede plegarse formando estructuras tridimensionales que pueden regular regiones muy lejanas. |
|
|
|
En resumen, el conjunto de metabolitos que han sido asociados a la obesidad y diabetes pueden darnos información muy valiosa sobre las vías metabólicas alteradas durante el desarrollo de estas enfermedades. Además, estos metabolitos podrán ser utilizados en un futuro como biomarcadores para el diagnóstico de una enfermedad con el fin de dar un tratamiento más adecuado correspondiente a la vía metabólica afectada o bien podrán servir como indicadores para prevenir enfermedades que se puedan presentar en un futuro.
Epigenómica
Anteriormente, se pensaba que el ADN era una estructura simple y lineal. Sin embargo, en las últimas décadas se ha demostrado que el ADN puede plegarse formando estructuras tridimensionales que pueden regular regiones muy lejanas. La secuencia de nucleótidos, entonces, no es lo único que regula la expresión génica, sino el enrollamiento del ADN y su posicionamiento durante la formación de estructuras complejas que construyen a los cromosomas.
La epigenética se refiere al conjunto de procesos por medio de los cuales se regula la transcripción de los genes sin afectar la secuencia del ADN. Los mecanismos principales por los que se llevan a cabo estas regulaciones del genoma son la adición de grupos metilo (metilación) de los nucleótidos del ADN y la metilación o adición de grupos acetilo (acetilación) de las histonas (proteínas sobre las cuales se enrolla el ADN durante la formación de los cromosomas) (Burdge y Lillycrop, 2014; Desai, Jellyman y Ross, 2015). La epigenómica representa a los cambios epigenéticos globales en una muestra, en un momento dado y en condiciones fisiopatológicas específicas. Por ejemplo, un estudio reveló que la piel que ha sido expuesta al sol sin protección tiene, en su ADN, menos grupos metilos que la piel que ha sido protegida del sol (Vandiver
et al., 2015). Los mismos patrones con menor cantidad de grupos metilo se han reconocido para las células cancerosas en comparación con las células sanas. Así, la epigenómica de la exposición al sol y de la progresión del cáncer son similares; esta similitud puede ser la respuesta molecular de cómo el cáncer de piel se asocia a la exposición al sol sin protección.
Las técnicas por medio de las cuales se estudia el epigenoma son muy diversas. En primer lugar, para conocer los patrones de metilación en el ADN, se utiliza frecuentemente la “secuenciación con bisulfito”. También, se pueden emplear anticuerpos que se unan específicamente a los nucleótidos metilados para su reconocimiento (Han y He, 2016). En segundo lugar y para el caso de la modificación (metilación o acetilación) de histonas, se puede precipitar la cromatina utilizando anticuerpos que se unan específicamente a las histonas.

Imagen: GDJ.
Un ejemplo muy interesante de la aplicación de la epigenómica a la clínica es la llamada programación fetal. Esta trata del destino metabólico de los hijos que han sido expuestos a ciertas condiciones nutricias durante el desarrollo en el útero. Las investigaciones del caso de la hambruna holandesa de 1944 nos permitieron ver que los niños nacidos de madres desnutridas tenían mayor tendencia a la obesidad y enfermedades metabólicas en la vida adulta (Ravelli, Stein y Susser, 1976). Ahora sabemos que tanto la desnutrición como la obesidad de la madre en la etapa fetal influyen sobre la salud metabólica del niño, del adolescente y del adulto más adelante en la vida (Reichetzeder
et al., 2016). En diversos estudios se ha concluido que la dieta materna puede regular la transcripción de genes involucrados en la formación de tejido adiposo (adipogénesis), en la producción de lípidos (lipogénesis) y en el metabolismo de la glucosa. Un ejemplo de estos genes es el que codifica para la hormona leptina. La región que regula la transcripción del gen de la leptina tiene mayor número de grupos metilo después de consumir una dieta rica en grasas. Esta metilación incrementada provoca la disminución de la expresión del gen de leptina y, como consecuencia, existe menor concentración de esta hormona en suero (Milagro
et al., 2009) Debido a que la acción de la leptina es favorecer la saciedad, su menor concentración promueve mayor consumo de alimento y contribuye a la formación de tejido adiposo y como consecuencia, la obesidad.
Nutrigenómica y nutrigenética
La nutrigenómica es la herramienta que nos deja conocer, de manera global, los cambios en la expresión de genes en respuesta al consumo de un nutrimento, alimento o dieta. Por ejemplo, se sabe que el consumo de ácidos grasos poliinsaturados (AGPI) resulta en un beneficio para la salud cardiovascular. En un estudio se determinó la influencia del AGPI docosahexanoico y sus metabolitos sobre la expresión global de genes y se concluyó que los genes que participan en la formación de la placa de ateroma que bloquea las arterias se encuentra disminuida (Merched
et al., 2008). A partir de este tipo de trabajos, se ha visto que la dieta participa en los cambios de expresión de genes y que modifica el metabolismo.
Por otra parte, la nutrigenética se encarga de estudiar los efectos que tiene una variante genética sobre la respuesta del individuo a los nutrimentos. Existen referencias antiguas acerca de la variabilidad interindividual en respuesta a factores dietéticos, como la del poeta y filósofo griego Tito Lucrecio (99 a.C.-55 a.C.), quien citó: “Lo que para unos es comida, es amargo veneno para otros”.
La profundización en el estudio de las enfermedades asociadas a las variantes genéticas ha generado un mejor entendimiento de la influencia de los nutrimentos y de la dieta sobre el estado de salud y enfermedad de los humanos. Un ejemplo clínico es la fenilcetonuria, la cual representa un error innato del metabolismo dado por la presencia de mutaciones en el gen que codifica para la enzima hidroxilasa de la fenilalanina (Neeha y Kinth, 2013). Como consecuencia, esta enzima no es funcional, provocando que el metabolismo de dicho aminoácido se vea afectado y se acumule el fenilpiruvato, un metabolito neurotóxico. Los pacientes con diagnóstico de fenilcetonuria deben consumir una dieta restringida en el aminoácido fenilalanina para evitar el acúmulo del metabolito neurotóxico, el cual provoca retraso mental.
Debido que la nutrigenética se basa en los cambios de variantes presentes en el ADN, los cuales influyen en la manera en que se metabolizan los nutrimentos, las metodologías utilizadas para determinar cuestiones de nutrigenética son las mismas que en genómica. Por otra parte, dado que la nutrigenómica estudia el impacto de los nutrimentos sobre la expresión de genes, las tecnologías utilizadas para su análisis son las mismas que las de la transcriptómica.
Conclusiones
Las “ómicas” representan el análisis de un gran número de moléculas a partir de muestras biológicas, gracias al avance tecnológico que se ha dado en los últimos años y a la formación de equipos multidisciplinarios que ayudan a la interpretación de los datos. La creación de los biobancos ha logrado recaudar un gran número de muestras, las cuales han sido analizadas desde las diferentes “ómicas” (genómica, transcriptómica, proteómica, metabolómica, nutrigenómica, epigenómica, entre otras) para poder obtener nueva información de un fenómeno biológico. Hasta ahora, nos hemos beneficiado de estas ciencias para la creación de biomarcadores que se asocian o predicen un proceso biológico, ya sea normal o que conlleva a una enfermedad.
Se ha logrado estudiar cada “ómica” por separado, pero el reto será interrelacionar a todas estas disciplinas. De esta forma, el estudio de las “ómicas” permitirá entender la red de moléculas y de procesos biológicos que estén involucrados en un proceso biológico o en una enfermedad. Cuando esto suceda, podremos utilizar la información para el oportuno diagnóstico de una enfermedad, para la generación de medicamentos más específicos y para la creación de la medicina personalizada, la cual busca individualizar la atención de los pacientes por medio de la predicción, prevención y tratamiento de las enfermedades, con el conocimiento de los antecedentes genéticos, la exposición ambiental y la alimentación de cada individuo.
En un futuro, los sistemas de salud podrán utilizar la información obtenida a partir de las “ómicas” para tratar los padecimientos más frecuentes de una población utilizando la medicina personalizada. Al mismo tiempo, se debe de contemplar que los datos generados por las “ómicas” deberán de respetar los aspectos éticos y legales establecidos por la legislación, con el fin de proteger el anonimato de los individuos. Por esta razón, se ha publicado recientemente una revisión del estatus de las regulaciones de los biobancos en México (Motta-Murguia y Saruwatari-Zavala, 2016).
Bibliografía
Avery, O. T., MacLeod, C. M., y McCarty, M. (1944). Studies on the chemical nature of the substance inducingtransformation of pneumococcal types. Journal of Experimental Medicine, 79(2), 137–158. DOI: <http://doi.org/10.1084/jem.79.2.137>.
Bargalló-Rocha, J. E. et al. (2015). Cost-Effectiveness of the 21-Gene Breast Cancer Assay in Mexico. Advances in Therapy, 32(3), 239–253. DOI: <http://doi.org/10.1007/s12325-015-0190-8>.
Begum, F., Ghosh, D., Tseng, G. C. y Feingold, E. (2012). Comprehensive literature review and statistical considerations for GWAS meta-analysis. Nucleic Acids Research, 40(9), 3777–3784. DOI: <http://doi.org/10.1093/nar/gkr1255>.
Burdge, G. C. y Lillycrop, K. A. (2014). Environment-physiology, diet quality and energy balance: the influence of early life nutrition on future energy balance. Physiology y Behavior. DOI: <http://doi.org/10.1016/j.physbeh.2013.12.007>.
Chevalier, S., Marliss, Morais, Lamarche y Gougeon (2005). Whole-body protein anabolic response is resistant to the action of insulin in obese women. American Journal of Clinical Nutrition, 82(2), 355–365. DOI: <https://www.ncbi.nlm.nih.gov/pubmed>.
Corvol, H. et al. (2016). Translating the genetics of cystic fibrosis to personalized medicine. Translational Research. DOI: <http://doi.org/10.1016/j.trsl.2015.04.008>.
Desai, M., Jellyman, J. K. y Ross, M. G. (2015). Epigenomics, gestational programming and risk of metabolic syndrome. International Journal of Obesity. DOI: <http://doi.org/10.1038/ijo.2015.13>.
Fiehn, O., Timothy Garvey, W., Newman, J. W., Lok, K. H., Hoppel, C. L. y Adams, S. H. (2010). Plasma metabolomic profiles reflective of glucose homeostasis in non-diabetic and type 2 diabetic obese African-American women. PLoS ONE, 5(12), 1–10. DOI: <http://doi.org/10.1371/journal.pone.0015234>.
Gutierrez Aguilar, R., Kim, D. H., Woods, S. C. y Seeley, R. J. (2011). Expression of New Loci Associated With Obesity in Diet-Induced Obese Rats: From Genetics to Physiology. Obesity (Silver Spring). DOI: <https://doi.org/10.1038/oby.2011.236>.
Han, Y. y He, X. (2016). Integrating epigenomics into the understanding of biomedical insight. Bioinformatics and Biology Insights. Recuperado de: <https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5138066/>.
Harrow, J. et al. (2012). GENCODE: The reference human genome annotation for the ENCODE project. Genome Research, 22(9), 1760–1774. DOI: <http://doi.org/10.1101/gr.135350.111>.
Hershey, A. D. y Chase, M. (1952). Independent functions of viral protein and nucleic acid in growth of bacteriophage. Journal of General Physiology, 36(1), 39–56. Reciperado de: <https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2147348/>.
International Human Genome Sequencing Consortium. (2004). International Human Genome Sequencing Consortium. Finishing the euchromatic sequence of the human genome. Nature, 431, 931–945. Recuperado de: <http://www.nature.com/nature/journal/v431/n7011/full/nature03001.html?foxtrotcallback=true>.
Kosteria, I. et al. (2017). The use of proteomics in assisted reproduction. In Vivo, 31(3), 267–283. DOI: <http://doi.org/10.21873/invivo.11056>.
LaFramboise, T. (2009). Single nucleotide polymorphism arrays: A decade of biological, computational and technological advances. Nucleic Acids Research. DOI: <http://doi.org/10.1093/nar/gkp552>.
Manolio, T. A. (2010). Genomewide Association Studies and Assessment of the Risk of Disease. The New England Journal of Medicine, 363(2), 166–176. DOI: <http://doi.org/10.1056/NEJMra0905980>.
Merched, A. J. et al. (2008). Atherosclerosis: evidence for impairment of resolution of vascular inflammation governed by specific lipid mediators. The FASEB Journal, 22(10), 3595–3606. DOI: <http://doi.org/10.1096/fj.08-112201>.
Milagro, F. I. et al. (2009). High fat diet-induced obesity modifies the methylation pattern of leptin promoter in rats. Journal of Physiology and Biochemistry, 65(1), 1-9. Rrecuperado de: <http://www.ncbi.nlm.nih.gov/pubmed/19588726>.
Mishra, N. (2010). Introduction to Proteomics: Principles and Applications. Introduction to Proteomics: Principles and Applications. DOI: <http://doi.org/10.1002/9780470603871>.
Moore, S. C. et al. (2014). Human metabolic correlates of body mass index. Metabolomics, 10(2), 259–269. DOI: <http://doi.org/10.1007/s11306-013-0574-1>.
Moran-Ramos, S. et al. (2017). An amino acid signature associated with obesity predicts 2-year risk of hypertriglyceridemia in school-age children. Scientific Reports. Recuperado de: <https://www.nature.com/articles/s41598-017-05765-4>.
Motta Murguia, L. y Saruwatari-Zavala, G. (2016). Mexican Regulation of Biobanks. The Journal of Law, Medicine y Ethics : A Journal of the American Society of Law, Medicine y Ethics, 44(1), 58–67. Recuperado de: <https://www.ncbi.nlm.nih.gov/pubmed/27256124>.
Neeha, V. S. y Kinth, P. (2013). Nutrigenomics research: A review. Journal of Food Science and Technology, 50(3), 415–428. DOI: <http://doi.org/10.1007/s13197-012-0775-z>.
Omenn, G. S. et al. (2015). Metrics for the human proteome project 2015: Progress on the human proteome and guidelines for high-confidence protein identification. Journal of Proteome Research, 14(9), 3452–3460. DOI: <http://doi.org/10.1021/acs.jproteome.5b00499>.
Park, S., Sadanala, K. C. y Kim, E.-K. (2015). A Metabolomic Approach to Understanding the Metabolic Link between Obesity and Diabetes. Molecules and Cells. DOI: <http://doi.org/10.14348/molcells.2015.0126>.
Ravelli, G. P., Stein, Z. A. y Susser, M. W. (1976). Obesity in Young Men after Famine Exposure in Utero and Early Infancy. New England Journal of Medicine, 295(7), 349–353. DOI: <http://doi.org/10.1056/NEJM197608122950701>.
Reichetzeder, C. et al. (2016). Developmental Origins of Disease – Crisis Precipitates Change. Cellular Physiology and Biochemistry, 39(3), 919–938. DOI: <http://doi.org/10.1159/000447801>.
Vandiver, A. R., Irizarry, R. Hansen, K, Garza, L., Runarsson, A., Li, X., Chien, A., Wang, T., Leung, S. Kang, S y Feinberg, A. (2015). Age and sun exposure-related widespread genomic blocks of hypomethylation in nonmalignant skin. Genome Biology. DOI: <https://doi.org/10.1186/s13059-015-0644-y>.
Venter, J. C. et al. (2001). The sequence of the human genome. Science, 291(5507), 1304–1351. DOI: <http://doi.org/10.1126/science.1058040>.
Watson, J. D. y Crick, F. H. C. (1953). Molecular structure of nucleic acids. Nature. DOI: <http://doi.org/10.1097/BLO.0b013e3181468780>.















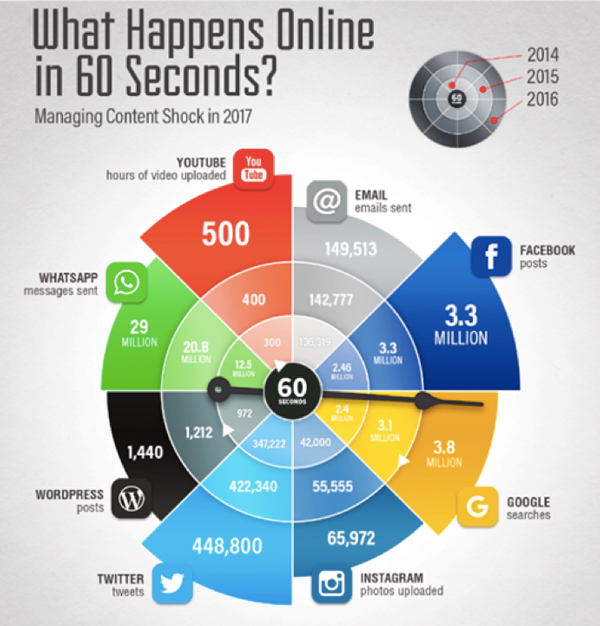 ¿Qué sucede en línea cada 60 segundos?
Fuente: Smart Insigts. Recuperado de:
¿Qué sucede en línea cada 60 segundos?
Fuente: Smart Insigts. Recuperado de: 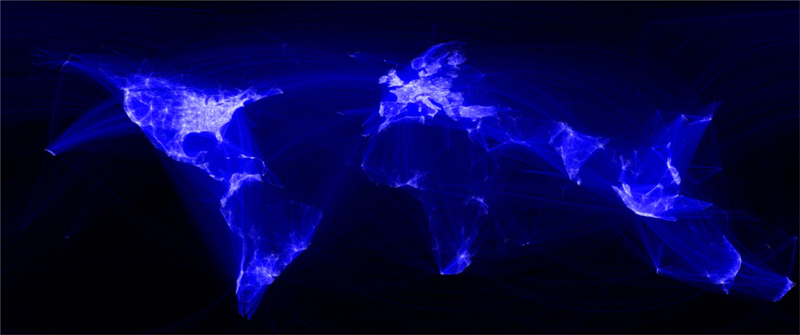 Interconexión de Facebook en el mundo.
Fuente:
Interconexión de Facebook en el mundo.
Fuente:  Imagen:
Imagen: 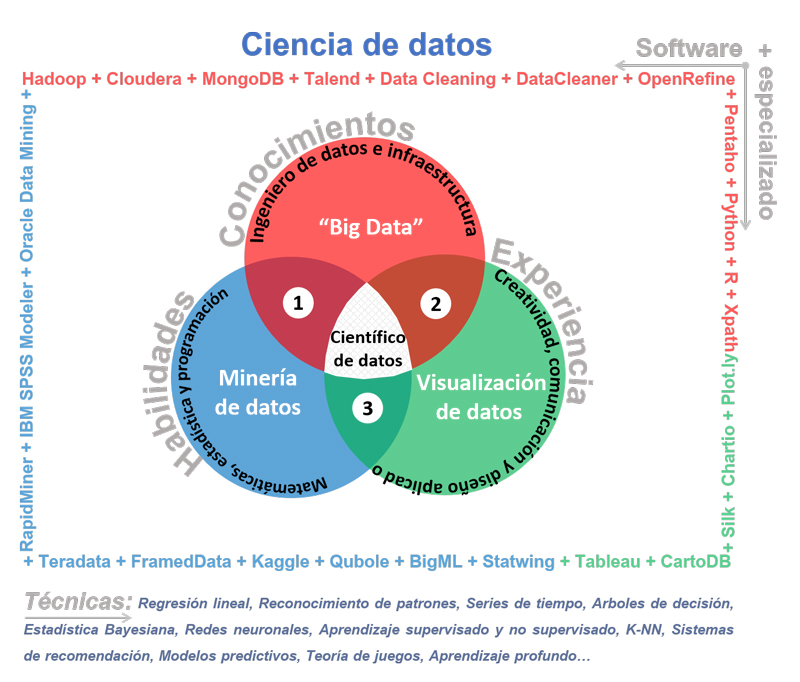 El científico de datos y su entorno.
Fuente: elaboración propia.
El científico de datos y su entorno.
Fuente: elaboración propia. Imagen:
Imagen:  Imagen:
Imagen:  Imagen:
Imagen: 


 Resumen
Introducción
De importancia social, personal y hasta…
Amateur, pero también barata y de…
Promover a las instituciones, el mandato
¿A quién le importa la ciencia hecha en…
A manera de conclusión
Bibliografía
Resumen
El 30.2% de los mexicanos asegura tener información “nula” con respecto a los avances de la ciencia… Desde hace mucho tiempo, en México y en el mundo en general, se ha asumido que la difusión del conocimiento científico es responsabilidad de aquellos que lo generan y que estar al tanto de los avances que se producen en este campo a nivel nacional es prácticamente una obligación del público. El resultado de esta visión ha sido que existan grandes sectores de la población mundial que, en términos generales, carecen por completo de cultura científica. Sin embargo, esta ineficaz forma de difundir el conocimiento está empezando a cambiar…
Palabras clave: comunicación de la ciencia, conocimiento científico, público, lectores, México.
Communication of science in Mexico, the contempt of public and private
30.2% of Mexicans claim to have “zero” information regarding the progress of science… For a long time, in Mexico and in the world in general, it has been assumed that the dissemination of scientific knowledge is the responsibility of those who generate it, and being aware of the advances that occur in this field is practically an obligation of the public. The result of this vision has been that there are large sectors of the world’s population that, in general terms, are completely lacking in scientific culture. However, this ineffective way of spreading knowledge is starting to change…
Keywords: communication science, scientific knowledge, public, readers, Mexico.
Introducción
La comunicación de la ciencia en México es y ha sido escasa y poco exitosa
porque no considera y en ocasiones hasta menosprecia a sus públicos.
Manuel Lino
Contaba el teórico Richard Feynman, considerado uno de los diez físicos más importantes de la historia, que su padre lo sentaba en su regazo y le leía artículos de la Enciclopedia Británica…
Estábamos leyendo –recuerda Feynman– sobre, digamos, dinosaurios. Acerca del Tyrannosaurus rex y (la enciclopedia) decía algo como ‘Este dinosaurio medía 7 metros y medio de altura, y su cabeza, dos metros de un extremo a otro’. Mi papá dejaba de leer y decía, ‘Ahora, veamos qué significa esto. Esto significa que si (el tiranosaurio) se parara en nuestro jardín, sería lo suficientemente alto como para asomarse por esta ventana de aquí’. Estábamos en el segundo piso. Y lo estaríamos viendo directamente a los ojos…
Resumen
Introducción
De importancia social, personal y hasta…
Amateur, pero también barata y de…
Promover a las instituciones, el mandato
¿A quién le importa la ciencia hecha en…
A manera de conclusión
Bibliografía
Resumen
El 30.2% de los mexicanos asegura tener información “nula” con respecto a los avances de la ciencia… Desde hace mucho tiempo, en México y en el mundo en general, se ha asumido que la difusión del conocimiento científico es responsabilidad de aquellos que lo generan y que estar al tanto de los avances que se producen en este campo a nivel nacional es prácticamente una obligación del público. El resultado de esta visión ha sido que existan grandes sectores de la población mundial que, en términos generales, carecen por completo de cultura científica. Sin embargo, esta ineficaz forma de difundir el conocimiento está empezando a cambiar…
Palabras clave: comunicación de la ciencia, conocimiento científico, público, lectores, México.
Communication of science in Mexico, the contempt of public and private
30.2% of Mexicans claim to have “zero” information regarding the progress of science… For a long time, in Mexico and in the world in general, it has been assumed that the dissemination of scientific knowledge is the responsibility of those who generate it, and being aware of the advances that occur in this field is practically an obligation of the public. The result of this vision has been that there are large sectors of the world’s population that, in general terms, are completely lacking in scientific culture. However, this ineffective way of spreading knowledge is starting to change…
Keywords: communication science, scientific knowledge, public, readers, Mexico.
Introducción
La comunicación de la ciencia en México es y ha sido escasa y poco exitosa
porque no considera y en ocasiones hasta menosprecia a sus públicos.
Manuel Lino
Contaba el teórico Richard Feynman, considerado uno de los diez físicos más importantes de la historia, que su padre lo sentaba en su regazo y le leía artículos de la Enciclopedia Británica…
Estábamos leyendo –recuerda Feynman– sobre, digamos, dinosaurios. Acerca del Tyrannosaurus rex y (la enciclopedia) decía algo como ‘Este dinosaurio medía 7 metros y medio de altura, y su cabeza, dos metros de un extremo a otro’. Mi papá dejaba de leer y decía, ‘Ahora, veamos qué significa esto. Esto significa que si (el tiranosaurio) se parara en nuestro jardín, sería lo suficientemente alto como para asomarse por esta ventana de aquí’. Estábamos en el segundo piso. Y lo estaríamos viendo directamente a los ojos…
 Foto: heimseiten_WebdesignKoeln.
Esta última frase no la dijeron ni Feynman ni su papá, sino Brian Malow, un stand up comedian estadounidense, conocido como Science Comedian, cuando me contaba sobre los cursos que imparte a científicos para que aprendan a dar charlas sobre divulgación.
En el final que cuenta Feynman (en What Do You Care what other People Think?, o Qué te importa lo que piensen los demás en español) su papá explicaba que, dado el tamaño de la cabeza del tiranosaurio, éste no podría meterla por la ventana, con lo cual el pequeño podría irse a dormir tranquilo.
Pero prefiero el final de Malow porque le da un toque artístico y dramático a esta historia sencilla que, en unos cuantos párrafos, condensa los principales elementos que debiera tener la comunicación de la ciencia para ser exitosa. El padre, Arthur Melville, explica el caso en términos que su público, el pequeño Richard, no sólo entienda, sino que pueda dimensionar y relacionar con su propio ambiente y experiencia. En su remate, Malow realza la parte narrativa, tanto en su aspecto formal –al hacernos notar que entre estos personajes hay un conflicto pues el tiranosaurio está mirando, quizá con hambre, a la familia Feynman–, como artístico al añadirle emoción e involucrarnos con la narración.
Pero el elemento que más quiero destacar de esta historia y sus dos finales es que la buena comunicación del conocimiento se hace en función del público; no de quien lo creó ni de quien lo comunica.
Así, con este sencillo ejemplo –que además sirve como introducción para este artículo– pretendo mostrar que la comunicación de la ciencia (considerada de manera amplia, desde la divulgación al periodismo) en México es todavía amateur y, por tanto, pobre en producción, calidad y recursos; y que esto se debe a que se ha ignorado y, en ocasiones, hasta menospreciado al público; además que nuestro sistema de ciencia, tecnología e innovación tiene fallas estructurales y conceptuales que han impedido, y quizá seguirán impidiendo, el adecuado desarrollo de esta actividad de enorme importancia para la que hay, aunque no lo crean, un público expectante.
De importancia social, personal y hasta íntima
Conocí a Malow en el “67 Lindau Nobel Laureate Meeting”, que este año 2017 reunió durante la última semana de junio, a 28 premios Nobel con alrededor de 400 jóvenes investigadores provenientes de más de 70 países que fueron seleccionados para asistir mediante concursos hechos por sus respectivas academias de ciencias. Estábamos además cerca de 90 reporteros y comunicadores de ciencia de 20 países.
[…] gracias a un diálogo entre científicos, políticos y sociedad exista una ciudadanía informada que contribuya a la generación de políticas públicas y a decidir el rumbo por el que habrá de transitar en temas relevantes.
Esta edición del encuentro fue dedicada a la Química, disciplina en la que la mayoría de los laureados asistentes ganaron sus respectivos Nobeles y en la que se especializaban los jóvenes investigadores. Sin embargo, el énfasis de la reunión se desplazó notablemente al revuelo que ha causado Donald Trump al negar, desde la oficina más poderosa del mundo, no sólo a la ciencia sino a la racionalidad misma.
La Casa Blanca se ha convertido en el principal baluarte de la “post-verdad” –término que ha sustituido a los clásicos “mentira”, “manipulación” y “demagogia”– y de las “dudas” respecto la evidencia científica del cambio climático, incluso la Presidencia de Estados Unidos de América (EUA) propuso cancelar el presupuesto federal destinado al combate de este problema; lo cual resulta alarmante si tomamos en cuenta que es el segundo país que más emite gases de efecto invernadero.
El tema se hizo presente desde la conferencia inaugural que estuvo a cargo de Steven Chu, Premio Nobel de Física de 1997 y Secretario de Energía de EUA de 2009 a principios de 2013 (Chu no pudo asistir a Lindau, su discurso fue leído por William Moerner, Nobel de Química de 2014).
Al principio advirtió acerca de las amenazas que nos acechan: “Hay un peligro real de que la elevación del nivel del mar o el colapso de la agricultura debido al calor y las sequías ocasionen migraciones masivas debidas al clima”; y, en ese sentido, calificó a los 4.5 millones de refugiados sirios, además de los millones de africanos que han salido de sus países natales, como apenas una “advertencia de lo que podría ocurrir en las próximas décadas”.
Foto: heimseiten_WebdesignKoeln.
Esta última frase no la dijeron ni Feynman ni su papá, sino Brian Malow, un stand up comedian estadounidense, conocido como Science Comedian, cuando me contaba sobre los cursos que imparte a científicos para que aprendan a dar charlas sobre divulgación.
En el final que cuenta Feynman (en What Do You Care what other People Think?, o Qué te importa lo que piensen los demás en español) su papá explicaba que, dado el tamaño de la cabeza del tiranosaurio, éste no podría meterla por la ventana, con lo cual el pequeño podría irse a dormir tranquilo.
Pero prefiero el final de Malow porque le da un toque artístico y dramático a esta historia sencilla que, en unos cuantos párrafos, condensa los principales elementos que debiera tener la comunicación de la ciencia para ser exitosa. El padre, Arthur Melville, explica el caso en términos que su público, el pequeño Richard, no sólo entienda, sino que pueda dimensionar y relacionar con su propio ambiente y experiencia. En su remate, Malow realza la parte narrativa, tanto en su aspecto formal –al hacernos notar que entre estos personajes hay un conflicto pues el tiranosaurio está mirando, quizá con hambre, a la familia Feynman–, como artístico al añadirle emoción e involucrarnos con la narración.
Pero el elemento que más quiero destacar de esta historia y sus dos finales es que la buena comunicación del conocimiento se hace en función del público; no de quien lo creó ni de quien lo comunica.
Así, con este sencillo ejemplo –que además sirve como introducción para este artículo– pretendo mostrar que la comunicación de la ciencia (considerada de manera amplia, desde la divulgación al periodismo) en México es todavía amateur y, por tanto, pobre en producción, calidad y recursos; y que esto se debe a que se ha ignorado y, en ocasiones, hasta menospreciado al público; además que nuestro sistema de ciencia, tecnología e innovación tiene fallas estructurales y conceptuales que han impedido, y quizá seguirán impidiendo, el adecuado desarrollo de esta actividad de enorme importancia para la que hay, aunque no lo crean, un público expectante.
De importancia social, personal y hasta íntima
Conocí a Malow en el “67 Lindau Nobel Laureate Meeting”, que este año 2017 reunió durante la última semana de junio, a 28 premios Nobel con alrededor de 400 jóvenes investigadores provenientes de más de 70 países que fueron seleccionados para asistir mediante concursos hechos por sus respectivas academias de ciencias. Estábamos además cerca de 90 reporteros y comunicadores de ciencia de 20 países.
[…] gracias a un diálogo entre científicos, políticos y sociedad exista una ciudadanía informada que contribuya a la generación de políticas públicas y a decidir el rumbo por el que habrá de transitar en temas relevantes.
Esta edición del encuentro fue dedicada a la Química, disciplina en la que la mayoría de los laureados asistentes ganaron sus respectivos Nobeles y en la que se especializaban los jóvenes investigadores. Sin embargo, el énfasis de la reunión se desplazó notablemente al revuelo que ha causado Donald Trump al negar, desde la oficina más poderosa del mundo, no sólo a la ciencia sino a la racionalidad misma.
La Casa Blanca se ha convertido en el principal baluarte de la “post-verdad” –término que ha sustituido a los clásicos “mentira”, “manipulación” y “demagogia”– y de las “dudas” respecto la evidencia científica del cambio climático, incluso la Presidencia de Estados Unidos de América (EUA) propuso cancelar el presupuesto federal destinado al combate de este problema; lo cual resulta alarmante si tomamos en cuenta que es el segundo país que más emite gases de efecto invernadero.
El tema se hizo presente desde la conferencia inaugural que estuvo a cargo de Steven Chu, Premio Nobel de Física de 1997 y Secretario de Energía de EUA de 2009 a principios de 2013 (Chu no pudo asistir a Lindau, su discurso fue leído por William Moerner, Nobel de Química de 2014).
Al principio advirtió acerca de las amenazas que nos acechan: “Hay un peligro real de que la elevación del nivel del mar o el colapso de la agricultura debido al calor y las sequías ocasionen migraciones masivas debidas al clima”; y, en ese sentido, calificó a los 4.5 millones de refugiados sirios, además de los millones de africanos que han salido de sus países natales, como apenas una “advertencia de lo que podría ocurrir en las próximas décadas”.
 Imagen: yatheesh_.
Luego se refirió a la multitud de avances científicos y tecnológicos que es necesario hacer para contribuir a que las energías limpias sean accesibles para cualquier uso a costos bajos, e invitó a los jóvenes químicos a desarrollar dichos avances. “Pero –dijo– también necesitamos políticas públicas estables a largo plazo que permitan financiar proyectos visionarios de investigación y desarrollo” y, agregaría, guiar las inversiones del sector privado hacia innovaciones a gran escala.
Al día siguiente, en un desayuno auspiciado por la representación de México, nuestro Nobel, Mario Molina, en referencia al tema comentó que: “es muy desafortunado, pero como científicos necesitamos unirnos y asegurarnos de que podemos comunicarle al público la enorme importancia que tiene la ciencia”. Y se preguntó: “¿Cómo nosotros, como comunidad científica, comunicamos este muy importante aspecto de la ciencia? Lo hacemos a la sociedad en general con la esperanza de que tengamos algún impacto en los tomadores de decisiones de ciertos gobiernos…”.
En otras palabras, tanto Chu como Molina, están aspirando al que se considera el resultado ideal de la comunicación de la ciencia, en especial del periodismo: que gracias a un diálogo entre científicos, políticos y sociedad exista una ciudadanía informada que contribuya a la generación de políticas públicas y a decidir el rumbo por el que habrá de transitar en temas relevantes.
El discurso de Chu además contenía el deseo de despertar vocaciones científicas (en este caso ya muy especializadas), otro de los beneficios que se espera de una comunicación de la ciencia eficaz.
Sin embargo, las respectivas audiencias de Chu y Molina eran reducidas (de alrededor de 500 personas en el primer caso y de unas 100 en el segundo). Resulta evidente que se requiere de alguna forma de comunicación para amplificar su mensaje y para comunicarse con la sociedad.
Pero, la comunicación de la ciencia… o mejor deberíamos decir la comunicación del conocimiento (para incluir a disciplinas como la Historia o la Economía) es importante también a nivel individual y hasta íntimo.
Como ejemplo quiero mencionar a Elizabeth Merab, reportera del Nation Media Group de Kenia, quien me explicó su razón personal para dedicarse al periodismo de ciencia. Merab padece anemia falciforme, un mal hereditario que no sería tan grave de no ser porque vive en uno de los países donde la malaria es endémica. Aquellos que son sólo portadores del gen de la anemia, pero no la padecen, tienen resistencia a la malaria; pero quienes sí la desarrollan corren grave riesgo de ser infectados por el Plasmodium falsiparum, lo cual es casi una sentencia de muerte.
He pasado alrededor de 75% de mi vida entrando y saliendo de hospitales y medicada […] Esto me hizo darme cuenta de que hay mucha gente que no sabe mucho sobre lo que consume en términos de medicamentos, ni de lo que consume de servicios y cuidados médicos.
[Además en Kenia] tenemos un cambio en la demografía […] pasamos de enfermedades infecciosas a no infecciosas, como el cáncer, la diabetes y la propia anemia […]. Estos males están al alza, y la población no tiene la información necesaria […] Información simple, como qué comer y qué no, dónde obtener tratamiento, el mal que tienes ¿lo cubre tu seguro? Así que sentí la necesidad de ser parte de esta conversación (Merab, 2017).
Se pueden mencionar muchas otras razones por las que comunicar ciencia es importante, pero quiero compartirles ésta que me dio Malow: “Si entiendes que toda la vida está relacionada, que nosotros estamos relacionados con esta planta y que toda la vida está hecha de las mismas cosas que el resto del universo, si entiendes ese tipo de unidad, las estúpidas cosas por las que nos peleamos, los prejuicios, que si eres gay y yo no, que si eres negro y yo blanco, yo soy judío y tú eres musulmán, entiendes que esas divisiones son tan ficticias […]. Quiero pensar que, si a más gente le importara la ciencia y sólo entender mejor el mundo, entonces esas diferencias se derrumbarían” (Malow, 2017).
Amateur, pero también barata y de baja calidad
A pesar de su enorme importancia (potencial), la comunicación de la ciencia en México y en América Latina es amateur y pobre.
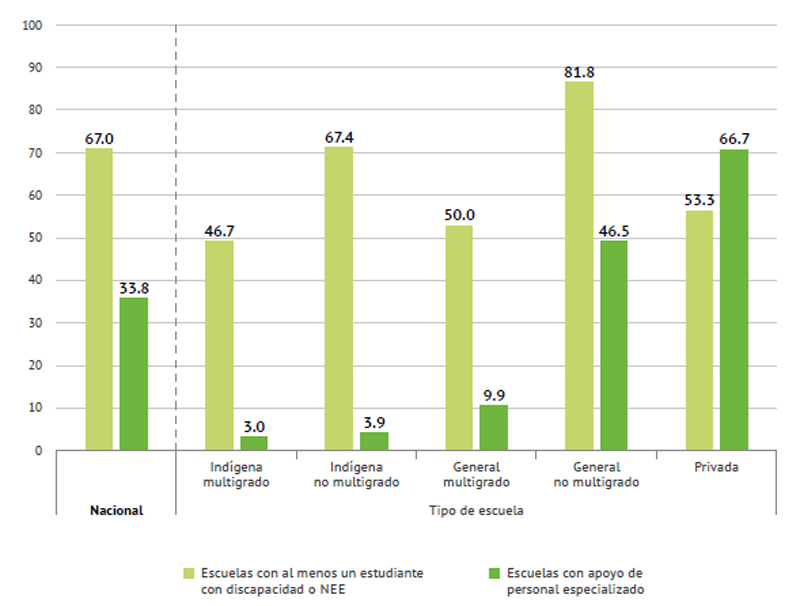
Hace pocas semanas, se presentó el Diagnóstico de la divulgación de la ciencia en América Latina (Patiño et al., 2017), hecho por la Red de Popularización de la Ciencia y la Tecnología en América Latina y el Caribe (RedPOP), un análisis que, entre otras cosas, confirma de manera científica lo que ya sabíamos: la poca profesionalización que existe en el medio.
En América Latina, apenas 10.1% de quienes hacen divulgación en las instituciones son profesionales (figura 1). Lo peor es que, cuando encomiendan (la palabra ‘contratan’ no parece aplicarse en estos casos) actividades a personas externas, menos de 1% son profesionales en la materia con un despacho u oficina (figura 2).
Imagen: yatheesh_.
Luego se refirió a la multitud de avances científicos y tecnológicos que es necesario hacer para contribuir a que las energías limpias sean accesibles para cualquier uso a costos bajos, e invitó a los jóvenes químicos a desarrollar dichos avances. “Pero –dijo– también necesitamos políticas públicas estables a largo plazo que permitan financiar proyectos visionarios de investigación y desarrollo” y, agregaría, guiar las inversiones del sector privado hacia innovaciones a gran escala.
Al día siguiente, en un desayuno auspiciado por la representación de México, nuestro Nobel, Mario Molina, en referencia al tema comentó que: “es muy desafortunado, pero como científicos necesitamos unirnos y asegurarnos de que podemos comunicarle al público la enorme importancia que tiene la ciencia”. Y se preguntó: “¿Cómo nosotros, como comunidad científica, comunicamos este muy importante aspecto de la ciencia? Lo hacemos a la sociedad en general con la esperanza de que tengamos algún impacto en los tomadores de decisiones de ciertos gobiernos…”.
En otras palabras, tanto Chu como Molina, están aspirando al que se considera el resultado ideal de la comunicación de la ciencia, en especial del periodismo: que gracias a un diálogo entre científicos, políticos y sociedad exista una ciudadanía informada que contribuya a la generación de políticas públicas y a decidir el rumbo por el que habrá de transitar en temas relevantes.
El discurso de Chu además contenía el deseo de despertar vocaciones científicas (en este caso ya muy especializadas), otro de los beneficios que se espera de una comunicación de la ciencia eficaz.
Sin embargo, las respectivas audiencias de Chu y Molina eran reducidas (de alrededor de 500 personas en el primer caso y de unas 100 en el segundo). Resulta evidente que se requiere de alguna forma de comunicación para amplificar su mensaje y para comunicarse con la sociedad.
Pero, la comunicación de la ciencia… o mejor deberíamos decir la comunicación del conocimiento (para incluir a disciplinas como la Historia o la Economía) es importante también a nivel individual y hasta íntimo.
Como ejemplo quiero mencionar a Elizabeth Merab, reportera del Nation Media Group de Kenia, quien me explicó su razón personal para dedicarse al periodismo de ciencia. Merab padece anemia falciforme, un mal hereditario que no sería tan grave de no ser porque vive en uno de los países donde la malaria es endémica. Aquellos que son sólo portadores del gen de la anemia, pero no la padecen, tienen resistencia a la malaria; pero quienes sí la desarrollan corren grave riesgo de ser infectados por el Plasmodium falsiparum, lo cual es casi una sentencia de muerte.
He pasado alrededor de 75% de mi vida entrando y saliendo de hospitales y medicada […] Esto me hizo darme cuenta de que hay mucha gente que no sabe mucho sobre lo que consume en términos de medicamentos, ni de lo que consume de servicios y cuidados médicos.
[Además en Kenia] tenemos un cambio en la demografía […] pasamos de enfermedades infecciosas a no infecciosas, como el cáncer, la diabetes y la propia anemia […]. Estos males están al alza, y la población no tiene la información necesaria […] Información simple, como qué comer y qué no, dónde obtener tratamiento, el mal que tienes ¿lo cubre tu seguro? Así que sentí la necesidad de ser parte de esta conversación (Merab, 2017).
Se pueden mencionar muchas otras razones por las que comunicar ciencia es importante, pero quiero compartirles ésta que me dio Malow: “Si entiendes que toda la vida está relacionada, que nosotros estamos relacionados con esta planta y que toda la vida está hecha de las mismas cosas que el resto del universo, si entiendes ese tipo de unidad, las estúpidas cosas por las que nos peleamos, los prejuicios, que si eres gay y yo no, que si eres negro y yo blanco, yo soy judío y tú eres musulmán, entiendes que esas divisiones son tan ficticias […]. Quiero pensar que, si a más gente le importara la ciencia y sólo entender mejor el mundo, entonces esas diferencias se derrumbarían” (Malow, 2017).
Amateur, pero también barata y de baja calidad
A pesar de su enorme importancia (potencial), la comunicación de la ciencia en México y en América Latina es amateur y pobre.
Hace pocas semanas, se presentó el Diagnóstico de la divulgación de la ciencia en América Latina (Patiño et al., 2017), hecho por la Red de Popularización de la Ciencia y la Tecnología en América Latina y el Caribe (RedPOP), un análisis que, entre otras cosas, confirma de manera científica lo que ya sabíamos: la poca profesionalización que existe en el medio.
En América Latina, apenas 10.1% de quienes hacen divulgación en las instituciones son profesionales (figura 1). Lo peor es que, cuando encomiendan (la palabra ‘contratan’ no parece aplicarse en estos casos) actividades a personas externas, menos de 1% son profesionales en la materia con un despacho u oficina (figura 2).
 Elaboración propia con datos del Diagnóstico de la divulgación de la ciencia en América Latina.
Elaboración propia con datos del Diagnóstico de la divulgación de la ciencia en América Latina.
 Elaboración propia con datos del Diagnóstico de la divulgación de la ciencia en América Latina.
El Diagnóstico revela que: “es notable que 60.2% de las instituciones de la muestra del presente estudio cuente sólo con personal que realiza sus actividades de divulgación de la ciencia de manera gratuita, y que 91.9% lo haga con al menos una parte de personal voluntario” (Patiño et al., 2017, p. 97). Además, encuentra que de quienes se dedican a estas actividades, “sólo 35.6% lo hace de tiempo completo”.
Esas y otras cifras pueden “ser indicativas de un bajo nivel de profesionalización en el recurso humano para la divulgación en la región” (Patiño et al., 2017, p. 123).
Lo que a los autores del Diagnóstico (Ma. de Lourdes Patiño Barba, Jorge Padilla González y Luisa Massarani) les parece simplemente “notable” a mí me parece francamente alarmante y hasta escandaloso. La misión de las universidades (es lo que son la mayoría de las instituciones a las que se refieren el estudio) se ha separado tradicionalmente en tres grandes ramas: investigación, docencia y extensión; y que las universidades dejen una parte medular de sus labores a los amateurs es una omisión gravísima.
La palabra “profesional” se refiere sobre todo a que un trabajo se haga a cambio de una remuneración, en contraste con el “amateur” que lo hace de forma gratuita; sin embargo, no es en balde que el término profesional también haga referencia a lo bien hecho y a quien “ejerce su profesión con capacidad y aplicación relevantes”, según la Real Academia Española. En ese sentido, una baja profesionalización implica también una baja (o simplemente menor) calidad en el trabajo.
Para colmo, como aseguran los investigadores Tomás Ejea y Bianca Garduño sobre la extensión cultural, “una exploración bibliográfica sistemática sobre el tema pone en evidencia la falta de consenso en la formulación de la conceptualización de sus tareas y sus objetivos”, por lo que las acciones en la materia no se desarrollan de acuerdo a programas estructurados ni se tienen objetivos definidos y “carecen de presencia específica en la normativa universitaria, por lo que se subordinan a las autoridades. Por esta razón, el énfasis varía dependiendo de la importancia que le dé el funcionario en turno” (Ejea y Garduño, 2014, p. 14).
Promover a las instituciones, el mandato
Entre las conclusiones del Diagnóstico también podemos leer que “los tópicos sólo mínimamente se definen a partir de la detección de las necesidades e intereses de los públicos a los cuales se dirigen las acciones” (Patiño et al., 2017, p. 125).
En el caso de México, no atender con la comunicación de la ciencia los intereses del público sino los de las instituciones es, en cierto sentido, un mandato de ley.
Como señala el investigador y periodista Carlos Enrique Orozco, desde la fundación del Consejo Nacional de Ciencia y Tecnología (CONACYT), a finales de 1970, se mencionó entre sus funciones la de “fomentar la difusión sistemática de los trabajos realizados tanto por los investigadores nacionales como por los extranjeros que residen en el país, mediante la utilización de los medios más adecuados a ello” (Diario Oficial de la Federación, 1970, 29 de diciembre).
En esa redacción no quedaba claro si la difusión debía orientarse a la sociedad o a la comunidad científica. Pero diez años después, aunque no se le dio lugar en el Programa Nacional de Ciencia y Tecnología (1978-1982) quedó claro que el énfasis estaba en la sociedad. Como muestra, Orozco cita el aumento de tiraje de la revista Ciencia y desarrollo de 6 000 ejemplares bimestrales en 1978 a 65 000 en 1980, además de la gran cantidad de libros de divulgación y ciencia ficción que el CONACYT publicó.
Elaboración propia con datos del Diagnóstico de la divulgación de la ciencia en América Latina.
El Diagnóstico revela que: “es notable que 60.2% de las instituciones de la muestra del presente estudio cuente sólo con personal que realiza sus actividades de divulgación de la ciencia de manera gratuita, y que 91.9% lo haga con al menos una parte de personal voluntario” (Patiño et al., 2017, p. 97). Además, encuentra que de quienes se dedican a estas actividades, “sólo 35.6% lo hace de tiempo completo”.
Esas y otras cifras pueden “ser indicativas de un bajo nivel de profesionalización en el recurso humano para la divulgación en la región” (Patiño et al., 2017, p. 123).
Lo que a los autores del Diagnóstico (Ma. de Lourdes Patiño Barba, Jorge Padilla González y Luisa Massarani) les parece simplemente “notable” a mí me parece francamente alarmante y hasta escandaloso. La misión de las universidades (es lo que son la mayoría de las instituciones a las que se refieren el estudio) se ha separado tradicionalmente en tres grandes ramas: investigación, docencia y extensión; y que las universidades dejen una parte medular de sus labores a los amateurs es una omisión gravísima.
La palabra “profesional” se refiere sobre todo a que un trabajo se haga a cambio de una remuneración, en contraste con el “amateur” que lo hace de forma gratuita; sin embargo, no es en balde que el término profesional también haga referencia a lo bien hecho y a quien “ejerce su profesión con capacidad y aplicación relevantes”, según la Real Academia Española. En ese sentido, una baja profesionalización implica también una baja (o simplemente menor) calidad en el trabajo.
Para colmo, como aseguran los investigadores Tomás Ejea y Bianca Garduño sobre la extensión cultural, “una exploración bibliográfica sistemática sobre el tema pone en evidencia la falta de consenso en la formulación de la conceptualización de sus tareas y sus objetivos”, por lo que las acciones en la materia no se desarrollan de acuerdo a programas estructurados ni se tienen objetivos definidos y “carecen de presencia específica en la normativa universitaria, por lo que se subordinan a las autoridades. Por esta razón, el énfasis varía dependiendo de la importancia que le dé el funcionario en turno” (Ejea y Garduño, 2014, p. 14).
Promover a las instituciones, el mandato
Entre las conclusiones del Diagnóstico también podemos leer que “los tópicos sólo mínimamente se definen a partir de la detección de las necesidades e intereses de los públicos a los cuales se dirigen las acciones” (Patiño et al., 2017, p. 125).
En el caso de México, no atender con la comunicación de la ciencia los intereses del público sino los de las instituciones es, en cierto sentido, un mandato de ley.
Como señala el investigador y periodista Carlos Enrique Orozco, desde la fundación del Consejo Nacional de Ciencia y Tecnología (CONACYT), a finales de 1970, se mencionó entre sus funciones la de “fomentar la difusión sistemática de los trabajos realizados tanto por los investigadores nacionales como por los extranjeros que residen en el país, mediante la utilización de los medios más adecuados a ello” (Diario Oficial de la Federación, 1970, 29 de diciembre).
En esa redacción no quedaba claro si la difusión debía orientarse a la sociedad o a la comunidad científica. Pero diez años después, aunque no se le dio lugar en el Programa Nacional de Ciencia y Tecnología (1978-1982) quedó claro que el énfasis estaba en la sociedad. Como muestra, Orozco cita el aumento de tiraje de la revista Ciencia y desarrollo de 6 000 ejemplares bimestrales en 1978 a 65 000 en 1980, además de la gran cantidad de libros de divulgación y ciencia ficción que el CONACYT publicó.
 Ciencias Naturales IV. Imagen: Lewis Minor.
Ya para el Programa Nacional de Desarrollo Tecnológico y Científico (1984-1988) se empezó a usar el término comunicación social. Aun así, hasta el Programa Especial de Ciencia, Tecnología e Innovación, publicado en 2008, la postura de CONACYT, aunque con un lenguaje distinto, siguió siendo la misma: se trataba de “promover la cultura científica, tecnológica y de innovación a través de los medios de comunicación electrónicos e impresos, difundiendo los resultados de las investigaciones exitosas y el impacto social en la solución de problemas nacionales”.
Lo anterior significa, como diría Arthur Feynman, que la finalidad de las publicaciones no era la de satisfacer los intereses del público ni contribuir a la generación de una cultura científica, sino dar a conocer las acciones que llevaban a cabo las instituciones.
Sin embargo, en el Programa Especial de Ciencia, Tecnología e Innovación 2014-2018 (PECITI) la postura cambia. En primer lugar, se delinea la utilidad que, como nación, se puede encontrar en la comunicación de la ciencia. “Aquellos países que han logrado robustecer la apropiación social del conocimiento se caracterizan por ser más innovadores y en consecuencia aceleran su crecimiento económico” (PECITI, 2014, p. 16).
En segundo lugar, puntualiza que “para este fin es necesario fortalecer dos mecanismos que incrementen la cultura científica de los mexicanos y conduzcan a una mayor apropiación social de la ciencia y del conocimiento: la divulgación y comunicación, y el acceso al conocimiento” (PECITI, 2014, p. 16).
Es decir, el foco se desplaza de “dar a conocer los resultados de los investigadores” hacia el público. Éste es un cambio saludable. Pero en el mismo documento aparece otra vez lo que considero el otro gran error que se ha cometido desde el principio: “Dentro del SNCTI (Sistema Nacional de Ciencia, Tecnología e Innovación), el CONACYT es el principal encargado de las estrategias de divulgación. En ese sentido, ha realizado una amplia y continua labor para fortalecer la comunicación y divulgación de ciencia, tecnología e innovación (CTI), tales como: la creación de revistas (Ciencia y Desarrollo, Información Científica y Técnica ICyT, Comunidad CONACYT o TecnoIndustria), y la creación de la Semana Nacional de la Ciencia y la Tecnología”. También se creó la Agencia Informativa CONACYT para dar a conocer el trabajo de “individuos o empresas que estén creando ciencia, tecnología o innovación en México”.
[…] si queremos que haya una cultura científica, la comunicación de la ciencia no se debería distinguir del cine o la literatura, debe ser atractiva por sí misma porque no existe, ni podría aceptarse, la obligación de acercarse a ella. Esto sólo se hará por gusto, si el conocimiento científico se nos presenta de manera interesante, sorprendente, entretenida, conmovedora o hasta trascendente.
Es decir, el CONACYT, como “el principal encargado de las estrategias de divulgación”, asume que la mejor estrategia es ser también el principal productor de divulgación, ser el protagonista de la historia en lugar de apoyar a quienes quieran invertir, producir y generar contenidos de comunicación de la ciencia.
Es cierto que, desde hace unos años, se publica la “Convocatoria de Apoyo a Proyectos de Comunicación Pública de la Ciencia, la Tecnología y la Innovación”, que apoya una multitud de iniciativas.
Pero, una vez más, hay un pero: el financiamiento de estas iniciativas se hace a fondo perdido y dentro de las consideraciones de asignación de estos apoyos no se considera que los proyectos tengan (o vayan a tener en algún momento) un modelo de negocios que les permita subsistir y continuar con su labor una vez que termine el año durante el cual los apoya CONACYT.
Quiero aclarar que no comulgo con el “capitalismo salvaje” ni creo que deba desaparecer todo aquello que no produce dinero. Estoy de acuerdo en que el estado debe financiar actividades importantes y valiosas que no tengan perspectivas claras de generar capital (como la ciencia básica). Pero en este país hay que admitir que llega un momento en que la aceptación del público de un determinado producto (sí, también de un producto cultural) se mide por si gasta su dinero en él o no.
Resulta curioso que una convocatoria que lleva en el nombre la palabra “innovación”, que implica llevar un producto o mejora al mercado, no considere a los mercados.
Y, con perdón de los encargados del programa de apoyos, resulta hasta ridículo que en el primer párrafo de la convocatoria se asegure que “la nación en su conjunto, debe invertir en actividades y servicios que generen valor agregado de una forma sostenible” (sic por la coma que malamente separa el sujeto del predicado), y acto seguido ofrezca apoyo a proyectos que, en principio, no son ni tienen forma de volverse sostenibles.
Como remate, unas páginas más adelante encontramos el siguiente párrafo: “Las propuestas deberán estar estructuradas para comunicar a públicos segmentados o sectoriales los hallazgos o innovaciones más impactantes de las investigaciones científicas o los desarrollos tecnológicos, respectivamente, realizados por investigadores o empresas en instituciones establecidas en México”.
Ahí está, otra vez, el afán de autopromoción y el menosprecio al público. Ante ello, cabe señalar que muchos de los científicos más reconocidos de México han hecho sus descubrimientos más importantes en el extranjero. Aquí pongo algunos ejemplos notables:
Mario Molina, en la Universidad de California en Irvine, junto con el Profesor F. Sherwood Rowland; Francisco Bolívar Zapata (Premio Príncipe de Asturias 1991) estaba en San Francisco, California, cuando formó parte del equipo pionero que creó el primer organismo con ingeniería genética; Luis Herrera-Estrella participó en la elaboración de la primera planta genéticamente modificada mientras estaba en la Universidad Ghent, Bélgica, en el laboratorio de Marc Van Montagu; y Ricardo Miledi (ganador también del Asturias) descifró, con Bernard Katz en el University College London, los secretos de la transmisión sináptica que le dieron una tercera parte del Nobel a Katz.
¿A quién le importa la ciencia hecha en México?
Como periodista de ciencia y cultura he escuchado con (demasiada) frecuencia que los mexicanos “debemos conocer la ciencia que se hace en México”. Encuentro esta proposición tan ridícula como cuando hace unos años escuchaba que apoyáramos al cine mexicano y lo fuéramos a ver. Si las películas mexicanas no nos resultaban entretenidas, interesantes, conmovedoras ni sublimes, como público no teníamos razón alguna para verlas.
En ese sentido, si queremos que haya una cultura científica, la comunicación de la ciencia no se debería distinguir del cine o la literatura, debe ser atractiva por sí misma porque no existe, ni podría aceptarse, la obligación de acercarse a ella. Esto sólo se hará por gusto, si el conocimiento científico se nos presenta de manera interesante, sorprendente, entretenida, conmovedora o hasta trascendente. Y esto no va a suceder mientras no se haga de manera profesional, es decir, mientras quienes lo hagan no piensen en crear productos tan buenos que la gente esté dispuesta a pagar por ellos.
Porque el público sí está interesado en la ciencia. La Encuesta sobre la Percepción Pública de la Ciencia y la Tecnología (ENPECYT) que hace el Instituto Nacional de Estadística y Geografía (INEGI), por encargo de CONACYT, revela que es uno de los temas que aparecen en medios de comunicación que más le importa a la gente. El rubro ‘Nuevos inventos, descubrimientos científicos y desarrollo tecnológico’ aparece en segundo lugar de interés.
Además, algunos otros temas que importan a la gente también están relacionados con la ciencia, como el medio ambiente y, aunque la ENPECYT no pregunta al respecto, la salud, el comportamiento humano, etcétera.
Temas que interesan al público
Ciencias Naturales IV. Imagen: Lewis Minor.
Ya para el Programa Nacional de Desarrollo Tecnológico y Científico (1984-1988) se empezó a usar el término comunicación social. Aun así, hasta el Programa Especial de Ciencia, Tecnología e Innovación, publicado en 2008, la postura de CONACYT, aunque con un lenguaje distinto, siguió siendo la misma: se trataba de “promover la cultura científica, tecnológica y de innovación a través de los medios de comunicación electrónicos e impresos, difundiendo los resultados de las investigaciones exitosas y el impacto social en la solución de problemas nacionales”.
Lo anterior significa, como diría Arthur Feynman, que la finalidad de las publicaciones no era la de satisfacer los intereses del público ni contribuir a la generación de una cultura científica, sino dar a conocer las acciones que llevaban a cabo las instituciones.
Sin embargo, en el Programa Especial de Ciencia, Tecnología e Innovación 2014-2018 (PECITI) la postura cambia. En primer lugar, se delinea la utilidad que, como nación, se puede encontrar en la comunicación de la ciencia. “Aquellos países que han logrado robustecer la apropiación social del conocimiento se caracterizan por ser más innovadores y en consecuencia aceleran su crecimiento económico” (PECITI, 2014, p. 16).
En segundo lugar, puntualiza que “para este fin es necesario fortalecer dos mecanismos que incrementen la cultura científica de los mexicanos y conduzcan a una mayor apropiación social de la ciencia y del conocimiento: la divulgación y comunicación, y el acceso al conocimiento” (PECITI, 2014, p. 16).
Es decir, el foco se desplaza de “dar a conocer los resultados de los investigadores” hacia el público. Éste es un cambio saludable. Pero en el mismo documento aparece otra vez lo que considero el otro gran error que se ha cometido desde el principio: “Dentro del SNCTI (Sistema Nacional de Ciencia, Tecnología e Innovación), el CONACYT es el principal encargado de las estrategias de divulgación. En ese sentido, ha realizado una amplia y continua labor para fortalecer la comunicación y divulgación de ciencia, tecnología e innovación (CTI), tales como: la creación de revistas (Ciencia y Desarrollo, Información Científica y Técnica ICyT, Comunidad CONACYT o TecnoIndustria), y la creación de la Semana Nacional de la Ciencia y la Tecnología”. También se creó la Agencia Informativa CONACYT para dar a conocer el trabajo de “individuos o empresas que estén creando ciencia, tecnología o innovación en México”.
[…] si queremos que haya una cultura científica, la comunicación de la ciencia no se debería distinguir del cine o la literatura, debe ser atractiva por sí misma porque no existe, ni podría aceptarse, la obligación de acercarse a ella. Esto sólo se hará por gusto, si el conocimiento científico se nos presenta de manera interesante, sorprendente, entretenida, conmovedora o hasta trascendente.
Es decir, el CONACYT, como “el principal encargado de las estrategias de divulgación”, asume que la mejor estrategia es ser también el principal productor de divulgación, ser el protagonista de la historia en lugar de apoyar a quienes quieran invertir, producir y generar contenidos de comunicación de la ciencia.
Es cierto que, desde hace unos años, se publica la “Convocatoria de Apoyo a Proyectos de Comunicación Pública de la Ciencia, la Tecnología y la Innovación”, que apoya una multitud de iniciativas.
Pero, una vez más, hay un pero: el financiamiento de estas iniciativas se hace a fondo perdido y dentro de las consideraciones de asignación de estos apoyos no se considera que los proyectos tengan (o vayan a tener en algún momento) un modelo de negocios que les permita subsistir y continuar con su labor una vez que termine el año durante el cual los apoya CONACYT.
Quiero aclarar que no comulgo con el “capitalismo salvaje” ni creo que deba desaparecer todo aquello que no produce dinero. Estoy de acuerdo en que el estado debe financiar actividades importantes y valiosas que no tengan perspectivas claras de generar capital (como la ciencia básica). Pero en este país hay que admitir que llega un momento en que la aceptación del público de un determinado producto (sí, también de un producto cultural) se mide por si gasta su dinero en él o no.
Resulta curioso que una convocatoria que lleva en el nombre la palabra “innovación”, que implica llevar un producto o mejora al mercado, no considere a los mercados.
Y, con perdón de los encargados del programa de apoyos, resulta hasta ridículo que en el primer párrafo de la convocatoria se asegure que “la nación en su conjunto, debe invertir en actividades y servicios que generen valor agregado de una forma sostenible” (sic por la coma que malamente separa el sujeto del predicado), y acto seguido ofrezca apoyo a proyectos que, en principio, no son ni tienen forma de volverse sostenibles.
Como remate, unas páginas más adelante encontramos el siguiente párrafo: “Las propuestas deberán estar estructuradas para comunicar a públicos segmentados o sectoriales los hallazgos o innovaciones más impactantes de las investigaciones científicas o los desarrollos tecnológicos, respectivamente, realizados por investigadores o empresas en instituciones establecidas en México”.
Ahí está, otra vez, el afán de autopromoción y el menosprecio al público. Ante ello, cabe señalar que muchos de los científicos más reconocidos de México han hecho sus descubrimientos más importantes en el extranjero. Aquí pongo algunos ejemplos notables:
Mario Molina, en la Universidad de California en Irvine, junto con el Profesor F. Sherwood Rowland; Francisco Bolívar Zapata (Premio Príncipe de Asturias 1991) estaba en San Francisco, California, cuando formó parte del equipo pionero que creó el primer organismo con ingeniería genética; Luis Herrera-Estrella participó en la elaboración de la primera planta genéticamente modificada mientras estaba en la Universidad Ghent, Bélgica, en el laboratorio de Marc Van Montagu; y Ricardo Miledi (ganador también del Asturias) descifró, con Bernard Katz en el University College London, los secretos de la transmisión sináptica que le dieron una tercera parte del Nobel a Katz.
¿A quién le importa la ciencia hecha en México?
Como periodista de ciencia y cultura he escuchado con (demasiada) frecuencia que los mexicanos “debemos conocer la ciencia que se hace en México”. Encuentro esta proposición tan ridícula como cuando hace unos años escuchaba que apoyáramos al cine mexicano y lo fuéramos a ver. Si las películas mexicanas no nos resultaban entretenidas, interesantes, conmovedoras ni sublimes, como público no teníamos razón alguna para verlas.
En ese sentido, si queremos que haya una cultura científica, la comunicación de la ciencia no se debería distinguir del cine o la literatura, debe ser atractiva por sí misma porque no existe, ni podría aceptarse, la obligación de acercarse a ella. Esto sólo se hará por gusto, si el conocimiento científico se nos presenta de manera interesante, sorprendente, entretenida, conmovedora o hasta trascendente. Y esto no va a suceder mientras no se haga de manera profesional, es decir, mientras quienes lo hagan no piensen en crear productos tan buenos que la gente esté dispuesta a pagar por ellos.
Porque el público sí está interesado en la ciencia. La Encuesta sobre la Percepción Pública de la Ciencia y la Tecnología (ENPECYT) que hace el Instituto Nacional de Estadística y Geografía (INEGI), por encargo de CONACYT, revela que es uno de los temas que aparecen en medios de comunicación que más le importa a la gente. El rubro ‘Nuevos inventos, descubrimientos científicos y desarrollo tecnológico’ aparece en segundo lugar de interés.
Además, algunos otros temas que importan a la gente también están relacionados con la ciencia, como el medio ambiente y, aunque la ENPECYT no pregunta al respecto, la salud, el comportamiento humano, etcétera.
Temas que interesan al público
 Dos temas relacionados con la ciencia, la contaminación ambiental y las novedades en ciencia y tecnología, figuran en los tres primeros lugares del interés del público. Aquí se muestran los datos graficados en orden descendente de lo que les parece más interesante. Fuente: realización propia con datos de la ENPECYT (2015).
Estadísticas aparte, quienes nos dedicamos a actividades “elevadas” relacionadas de alguna manera con las ciencias, la cultura o el arte, a veces se nos olvida que al público general también le interesan –y mucho– estos temas. Se nos olvida que todos somos público general (salvo en el área de nuestra especialidad) y que, en el fondo, todo ser humano, por el simple hecho de serlo, se interesa por los grandes temas a los que la ciencia está dando respuesta: “qué es la vida”, “qué es la conciencia”, “de dónde venimos”, “por qué nos comportamos de la forma en que lo hacemos”, etcétera.
Los temas que menos interesan
Dos temas relacionados con la ciencia, la contaminación ambiental y las novedades en ciencia y tecnología, figuran en los tres primeros lugares del interés del público. Aquí se muestran los datos graficados en orden descendente de lo que les parece más interesante. Fuente: realización propia con datos de la ENPECYT (2015).
Estadísticas aparte, quienes nos dedicamos a actividades “elevadas” relacionadas de alguna manera con las ciencias, la cultura o el arte, a veces se nos olvida que al público general también le interesan –y mucho– estos temas. Se nos olvida que todos somos público general (salvo en el área de nuestra especialidad) y que, en el fondo, todo ser humano, por el simple hecho de serlo, se interesa por los grandes temas a los que la ciencia está dando respuesta: “qué es la vida”, “qué es la conciencia”, “de dónde venimos”, “por qué nos comportamos de la forma en que lo hacemos”, etcétera.
Los temas que menos interesan
 Si graficamos los mismos datos pero en orden descendente por quienes manifestaron tener un interés nulo por los temas, vemos que la contaminación ambiental se mantiene en la preferencia del público seguido por Ciencias sociales e Historia. Curiosamente, la Política y las Ciencias exactas son en ambas gráficas las menos favorecidas por el público. Fuente: realización propia con datos de la ENPECYT (2015).
A manera de conclusión
Volvamos con la familia Feynman, a quienes dejamos en una situación comprometida… No, no me refiero al tiranosaurio en la ventana, sino a Arthur tratando de suavizar la imagen para que el pequeño Richard pueda dormir.
Era muy emocionante y muy, muy interesante pensar que hubo animales de tal magnitud –y que todos murieron y que nadie sabía por qué (ahora ya sabemos)–. Por eso no estaba asustado de que alguno de ellos fuera a llegar hasta mi ventana…
Así, Richard pudo dormir, creció y, en parte gracias a las enseñanzas de su padre, no sólo se convirtió en un gran físico sino en un excelente divulgador. Su libro Surely you’re joking Mr. Feynman (¿Está usted de broma, Sr. Feynman?) está calificado en Amazon como un best seller que tiene 4.5 estrellitas, de 5 posibles; igual que el más serio QED. The Strange Theory of Life and Matter, y el video en el que Richard habla de su padre, entre otros temas, tiene casi 916 000 visualizaciones en YouTube. Teniendo en cuenta que murió en 1988, que el pico de su fama estuvo en los años 60 y que en The Big Bang Theory sólo se le ha mencionado una media docena de veces, no está nada mal como para dar ejemplo de que hay público para la comunicación de la ciencia.
Y ya que nos preguntamos si Feynman estaba bromeando y que menciono a The Big Bang Theory, un último consejo de Malow: “Pero claro que ayuda sentir que lo que haces es importante. Quizá, si tan sólo cuento algunos chistes científicos y te hago reír, ya hice algo con un poco de sentido porque tal vez pensabas que la ciencia era aburrida y te hice reír con un humor muy geek. Aunque no te haya enseñado nada, tal vez sólo te enseñé una cosa, que la ciencia puede ser divertida”.
Bibliografía
La mayor parte de las ideas que vierto aquí no son mías sino de diversos investigadores (aunque quizá las he tergiversado un poco). Anoto aquí los cuatro textos que más consulté en la elaboración de este artículo:
Sobre la historia de la comunicación de la ciencia en México y sus obstáculos:
Orozco Martínez, Carlos Enrique (2014). “Sin embargo, se mueve. La divulgación de la ciencia en México”, en Hugo Edgardo Méndez Fierros y Felipe Cuamea Velázquez, coordinadores, Universidad, ciencia y Cultura: evaluaciones para un saber colectivo. Universidad Autónoma de Baja California, México. Pp. 77-110.
Sobre los problemas de las universidades para comunicar:
Tomás Ejea Mendoza y Bianca Garduño Bello (2014). “La extensión de la cultura universitaria en México: un ensayo sobre su historia conceptualización y relevancia”, en Hugo Méndez y Felipe Cuamea (eds.), Universidad, ciencia y cultura: evocaciones para un saber colectivo. Universidad Autónoma de Baja California. Mexicali, pp. 52-78.
Sobre la lamentablemente escasa pero muy deseable influencia que tiene el periodismo científico en las políticas públicas:
Rosen, Cecilia y Javier Crúz-Mena (2015). “El periodismo de ciencia en América Latina”, en Luisa Massarani (org.), RedPOP: 25 años de popularización de la ciencia en América Latina. RedPOP, Unesco, Primera edición Río de Janeiro, pp. 61-71.
Sobre la importancia de la narrativa en la comunicación y de la comunicación misma:
Aquiles Negrete Yankelevich (2012), La divulgación de la ciencia a través de formas narrativas. Colección Divulgación para divulgadores de la Dirección General de Divulgación de la Ciencia, UNAM. Primera Reimpresión.
Si graficamos los mismos datos pero en orden descendente por quienes manifestaron tener un interés nulo por los temas, vemos que la contaminación ambiental se mantiene en la preferencia del público seguido por Ciencias sociales e Historia. Curiosamente, la Política y las Ciencias exactas son en ambas gráficas las menos favorecidas por el público. Fuente: realización propia con datos de la ENPECYT (2015).
A manera de conclusión
Volvamos con la familia Feynman, a quienes dejamos en una situación comprometida… No, no me refiero al tiranosaurio en la ventana, sino a Arthur tratando de suavizar la imagen para que el pequeño Richard pueda dormir.
Era muy emocionante y muy, muy interesante pensar que hubo animales de tal magnitud –y que todos murieron y que nadie sabía por qué (ahora ya sabemos)–. Por eso no estaba asustado de que alguno de ellos fuera a llegar hasta mi ventana…
Así, Richard pudo dormir, creció y, en parte gracias a las enseñanzas de su padre, no sólo se convirtió en un gran físico sino en un excelente divulgador. Su libro Surely you’re joking Mr. Feynman (¿Está usted de broma, Sr. Feynman?) está calificado en Amazon como un best seller que tiene 4.5 estrellitas, de 5 posibles; igual que el más serio QED. The Strange Theory of Life and Matter, y el video en el que Richard habla de su padre, entre otros temas, tiene casi 916 000 visualizaciones en YouTube. Teniendo en cuenta que murió en 1988, que el pico de su fama estuvo en los años 60 y que en The Big Bang Theory sólo se le ha mencionado una media docena de veces, no está nada mal como para dar ejemplo de que hay público para la comunicación de la ciencia.
Y ya que nos preguntamos si Feynman estaba bromeando y que menciono a The Big Bang Theory, un último consejo de Malow: “Pero claro que ayuda sentir que lo que haces es importante. Quizá, si tan sólo cuento algunos chistes científicos y te hago reír, ya hice algo con un poco de sentido porque tal vez pensabas que la ciencia era aburrida y te hice reír con un humor muy geek. Aunque no te haya enseñado nada, tal vez sólo te enseñé una cosa, que la ciencia puede ser divertida”.
Bibliografía
La mayor parte de las ideas que vierto aquí no son mías sino de diversos investigadores (aunque quizá las he tergiversado un poco). Anoto aquí los cuatro textos que más consulté en la elaboración de este artículo:
Sobre la historia de la comunicación de la ciencia en México y sus obstáculos:
Orozco Martínez, Carlos Enrique (2014). “Sin embargo, se mueve. La divulgación de la ciencia en México”, en Hugo Edgardo Méndez Fierros y Felipe Cuamea Velázquez, coordinadores, Universidad, ciencia y Cultura: evaluaciones para un saber colectivo. Universidad Autónoma de Baja California, México. Pp. 77-110.
Sobre los problemas de las universidades para comunicar:
Tomás Ejea Mendoza y Bianca Garduño Bello (2014). “La extensión de la cultura universitaria en México: un ensayo sobre su historia conceptualización y relevancia”, en Hugo Méndez y Felipe Cuamea (eds.), Universidad, ciencia y cultura: evocaciones para un saber colectivo. Universidad Autónoma de Baja California. Mexicali, pp. 52-78.
Sobre la lamentablemente escasa pero muy deseable influencia que tiene el periodismo científico en las políticas públicas:
Rosen, Cecilia y Javier Crúz-Mena (2015). “El periodismo de ciencia en América Latina”, en Luisa Massarani (org.), RedPOP: 25 años de popularización de la ciencia en América Latina. RedPOP, Unesco, Primera edición Río de Janeiro, pp. 61-71.
Sobre la importancia de la narrativa en la comunicación y de la comunicación misma:
Aquiles Negrete Yankelevich (2012), La divulgación de la ciencia a través de formas narrativas. Colección Divulgación para divulgadores de la Dirección General de Divulgación de la Ciencia, UNAM. Primera Reimpresión.