


Resumen
Este artículo discute la difícil decisión de elegir una licenciatura al salir del bachillerato. A muchos jóvenes les cuesta trabajo encontrar un espacio o una profesión en donde sientan que pueden integrar sus múltiples talentos e inquietudes. En estas líneas, una joven explora estos desafíos, tratando de reconciliar su pasión por las ciencias sociales y el arte, en el contexto particular de la UNAM.Palabras clave: estudiante UNAM, vocación, carrera universitaria, elección.
Fit to a T. Choosing a bachelor’s degree that meets your needs
Many young people struggle to find the educational program that fully embraces their multiple talents and interests, especially in Mexico where undergraduate studies are highly specialized. This article reflects upon the difficulty of choosing a degree after finishing high school. In the following paragraphs, a young student at the National Autonomous University of México describes how she faced this challenge and shares her personal journey trying to reconcile a passion for social sciences and art.Keywords: student UNAM, vocation, university career, election.
Soy María León y estudio Ciencia Política en la Universidad Nacional Autónoma de México (UNAM). Me apasiona el arte, la animación y la información. Este mes, contribuí en la Revista Digital Universitaria con un video que pueden encontrar en la sección Caleidoscopio. Escribí este texto para explicar un poco el proceso detrás de la animación y para hablar de mi experiencia como universitaria en los semestres desde que inicié la carrera. Pueden encontrar otros ejemplos de mi trabajo en mi sitio web o en mi instagram @ca.ma.leon.
Decisiones…

Frustración. Ilustración: María León. Tomar decisiones nunca ha sido mi fuerte. Me enfrenté a un episodio de indecisión hace más o menos dos años, cuando por fin tuve que elegir la carrera y la universidad a la que ingresaría para cursar mi licenciatura. Estaba llenando la forma para solicitar admisión a la UNAM, pero no sabía a qué carrera. En ese momento me acordé de una escena de La campana de cristal –la novela de Sylvia Plath (2005)– en donde la protagonista se imagina a sí misma descansando a la sombra de un árbol de higo. Cada higo que cuelga del árbol representa una opción de vida: un higo es una vida en familia con hijos y un esposo, otro higo un futuro como poeta, otro una brillante investigadora, otro presagia viajes por todo el mundo, y así ad infinitum. Cuando los higos se pudren y se caen, la protagonista aún no ha elegido uno. Por quererlo todo, se queda sin nada (Zen Pencils tiene una versión ilustrada esta escena que me gusta mucho). Tras esta aterradora reflexión, todavía sin estar segura de lo que quería, cerré los ojos y elegí “Ciencia Política” de la lista de más de cien opciones que la UNAM ofrece.

¿Por qué se oculta la verdad? Ilustración: María León. Cuando comenzaron las clases me sentí un poco perdida. Primero, porque no sabía dónde estaban los baños, las copias, la biblioteca y la cafetería. No me había aprendido mi número de cuenta ni mis salones. Seguido se me olvidaba traer la tarea y siempre llegaba tarde, aunque supongo que eso les pasa a todos en su primer semestre. Pero a nivel interno no tenía claro porque iba a la facultad diario y si valdría la pena. Usaba todo mi tiempo para leer a Locke, a Rousseau y a Platón. Siempre me habían interesado los problemas sociales y quería aprender a resolverlos, pero también había otras cosas que me inquietaban. Me apasionaba el arte. Por muchos años, había dedicado mi tiempo libre a dibujar y pintar, y en el año antes de entrar a la UNAM había trabajado haciendo ilustraciones. No ayudaba que muchos profesores nos repetían constantemente que en cuanto nos graduáramos el mundo se nos vendría encima, por eso teníamos que ser los mejores en la carrera y trabajar hasta el cansancio para ser unos expertos. Yo no estaba segura si quería dedicar todo mi tiempo y energía a volverme una politóloga experta. Las ciencias sociales y el arte parecían existir en dos planos diferentes, y a mí me parecía triste tener que abandonar una cosa por la otra.
El puente mental que unió mis intereses aparentemente opuestos surgió de mi mayor frustración académica en la carrera. Me molestaba que una gran parte de los textos que teníamos que leer estuvieran escritos con lenguaje pretencioso, poco claro y complicado. ¿Que no se puede expresar el significado de la palabra “poder” o “Estado” de manera sencilla y accesible? Yo pienso que sí. En 1946 George Orwell (2017) escribió un ensayo en el que critica el lenguaje moderno por ser “feo e impreciso”. Para Orwell, esta complejidad innecesaria del lenguaje se debe al deseo de ocultarle a la población las condiciones actuales del mundo y las decisiones políticas poco éticas. La verdad es tan abominable que la única forma de lograr que la gente la acepte es ocultándola con el lenguaje. Yo añadiría que el lenguaje académico moderno, lleno de vaguedades y tecnicismos, sirve para limitar el acceso al conocimiento a aquellos que tienen el tiempo y la voluntad de descifrarlo.

Una nueva perspectiva. Ilustración: María León. El acceso a la información simple y clara se volvió algo fundamental para mí, y empecé a pensar en formas de democratizar lo que estaba aprendiendo en clase. Descubrí que, en muchas ocasiones, las imágenes logran abordar conceptos complicados de manera parsimoniosa y elegante. En algunas revistas encontré ejemplos perfectos del poder de las imágenes. Las caricaturas del New Yorker (@newyorkercatroons), por ejemplo, hacen críticas incisivas a los políticos estadounidenses con dibujos de líneas simples. Las animaciones de The Atlantic explican problemas sociales complejos –como el racismo, la secularización del medio oriente y el voto que apoyó a Trump– en dos minutos, utilizando lenguaje sencillo y abstracciones gráficas.
Pensé que crear contenido así era la mejor forma de unir mis dos grandes intereses. Gracias a mi formación de politóloga tendría las herramientas necesarias para extraer el conocimiento de textos abarrotados de tecnicismos, y con mis habilidades artísticas podría comunicar el contenido a una audiencia más amplia de forma atractiva. La animación que hice para la edición de septiembre-octubre de la Revista Digital Universitaria es uno de mis primeros intentos de hacer justamente esto: difundir conocimiento especializado a través del arte, y de paso, reconciliar mi vocación artística con mi carrera en Ciencia Política.

Ante la disyuntiva. Ilustración: María León. Ha sido una experiencia interesante tratar de encajar en la cajita definida de una licenciatura y darme cuenta de que no quepo ahí, como creo que les pasa a muchos otros estudiantes. La UNAM me ha dado la posibilidad de explorar esta incomodidad, aunque no de la forma que esperaba y no siempre dentro del espacio del salón de clases. Por ejemplo, de vez en cuando voy a alguna clase en la Facultad de Arte y Diseño para nutrir mi lado artístico, o me doy una vuelta por el Museo Universitario Arte Contemporáneo (MUAC), o tengo la oportunidad de participar en un proyecto como la RDU que me permite trabajar en las cosas que me interesan y me importan. La lección que yo me llevo de mi tiempo en la UNAM (y aquí me permito citar a mi tía) es que una carrera muchas veces es como un traje que te queda mal. Lo bueno es que siempre puedes modificarlo, cortarlo, o rellenarlo para que te quede a la medida.
Bibliografía
Orwell, George. 2017. The Collected Essays, Journalism, And Letters Of George Orwell, Vol. 4. Nueva York: Harcourt, Brace, Javanovich. p. 128.
Plath, Sylvia (2005). The Bell Jar. Nueva York: Harper Perennial Modern.


Un fuerte terremoto destruye de inmediato las
asociaciones más viejas: el mundo, el símbolo mismo de
todo lo que es sólido, se ha movido bajo nuestros pies
como una capa sobre un líquido; un segundo de tiempo le
ha transmitido a la mente una extraña idea de inseguridad,
que nunca habría surgido con horas de reflexión
Charles Darwin
Un huracán de pensamientos se libera después de cada
nuevo entendimiento. Este a su vez resulta en un
terremoto de premisas. Estos son los desastres naturales
que remodelan el espíritu
Vera Nazarian
19S
Amables lectores, debí haber escrito esta Editorial a principios de septiembre, pero la procrastinación que frecuentemente nos afecta me llevó a diferir el sentarme ante la página en blanco durante algunas semanas, hasta que el 19S nos impactó en la Ciudad de México. Ahora que escribo estas líneas es imposible no tocar el tema; si así lo hiciera, estaría faltando al respeto a los millones de personas afectadas por el terremoto, cuyos efectos continuamos procesando. En estos días he leído docenas de editoriales en los medios, que abordan el tema desde muchas perspectivas. Intentaré hacerlo con sensibilidad, sin restar énfasis en las lecciones a aprender, y situando algunos de los manuscritos que aparecen en este número de la Revista Digital Universitaria (RDU) en un panorama de utilidad y optimismo. Es fascinante cómo Charles Darwin capturó en unas líneas el brutal efecto de unos cuantos segundos en la vida de las personas, y cómo emerge esta profunda sensación de inseguridad que, como dice la cita: “nunca habría surgido con horas de reflexión”. En un breve intervalo de tiempo el contexto de muchísimas personas cambió radicalmente, y día a día nos preguntamos cómo podemos contribuir con nuestro grano de arena en el amplio horizonte de acciones posibles. Creo firmemente que las instituciones educativas y académicas, como la nuestra, están en una situación idónea para aportar ideas y acciones que promuevan el regreso a esa fluida y efímera situación que, a falta de otro descriptor, llamamos “normalidad”.El 19 de septiembre por la mañana, tuvimos una reunión de trabajo con nuestro Rector, el Dr. Enrique Graue Wiechers, otros rectores de universidades públicas y privadas de varios estados de la República, y con académicos y representantes de dichas entidades, para dar continuidad a una iniciativa de innovación educativa. Los detalles de la constitución de este grupo interuniversitario los comentaremos en el siguiente número de la RDU. Baste decir que ese día, en el agradable escenario de la Unidad de Seminarios “Ignacio Chávez” de la UNAM, se solidificó la gestación de una iniciativa que representa un poderoso ejemplo de trabajo en equipo, con creatividad y rigor académico, para desarrollar intervenciones en beneficio de los estudiantes de educación superior. Al final de esa productiva sesión, todos los presentes nos dirigimos a nuestras instituciones para participar en el macrosimulacro programado a las 11 de la mañana, que transcurrió “sin novedad”. Las personas que no habían nacido en 1985 y aquellos que ya teníamos consciencia en esa fecha, colaboramos de manera rutinaria en el proceso de este ejercicio, algunos sin tener muy claro de qué se trata este “ritual”, al que nos hemos acostumbrado en los últimos 32 años. Después de caminar ordenadamente a nuestros puntos de reunión y de platicar trivialidades, regresamos a nuestras áreas de trabajo muy quitados de la pena.
Sobra decir que todos los que vivimos en la sufrida Ciudad de México, al sentir el movimiento telúrico a las 13:14:40 horas del 19S, vivimos unos instantes de angustia y miedo, por el riesgo de morir, propio y de nuestros seres queridos, o de perder aquellos bienes materiales que, si bien son secundarios, tanto trabajo nos ha costado adquirir. Cada uno de nosotros tiene multitud de historias que contar sobre lo que experimentó en esos aciagos momentos, que nos hicieron –y nos siguen haciendo– repensar el total de nuestras prioridades vitales y personales. Con el paso de los días, la cifra creciente de personas fallecidas y heridas, de casas y edificios dañados, el retorno a la rutinaria normalidad se ve cada vez más lejano.
¿Qué aporta este número de la RDU?
Los manuscritos que integran este número de la revista ofrecen un caleidoscopio de áreas del conocimiento con intensa vigencia, originándose en diversas perspectivas del quehacer universitario y ofreciendo potenciales soluciones a problemas que aquejan a la sociedad moderna. A continuación, comentaré brevemente algunos de ellos, con la perspectiva particular a la que nos obliga la situación actual del país:“¿Qué tan derecho es el derecho a la educación en México?” ¡Qué tema tan ad hoc para empezar! Además de ser uno de los tópicos más apasionantes e importantes del discurso y acción social actuales, lo que nos llevó a agregar apartados educativos en la RDU para explorar estos temas desde diversas ópticas, es una de las esferas más directamente afectadas por el 19S. El análisis de este derecho, a la luz de los cuatro principios de los derechos humanos descritos por la autora: universalidad, indivisibilidad, interdependencia y progresividad, en el contexto de los desastres naturales, nos debe llevar a reflexionar profundamente sobre el tema y a hacer lo posible para que estos principios no sean sólo palabras vacías en nuestra Carta Magna. La pérdida de vidas en centros educativos, de estudiantes (niños, jóvenes y adultos), docentes, administrativos y trabajadores, así como los esfuerzos colectivos de la sociedad y las dependencias oficiales para rescatar con vida a los sobrevivientes, ha sido uno de los puntos más poderosos emocionalmente en este catastrófico evento. ¿Cómo borrar de nuestras mentes las imágenes y videos de las instalaciones educativas destruidas y gravemente dañadas?, ¿la expresión de angustia, miedo y dolor de los testigos de estos hechos y de los familiares de los afectados?, dicen que el tiempo sana todas las heridas, pero éstas son demasiado profundas como para no dejar cicatrices permanentes en nuestra psique individual y colectiva.
Uno de los efectos inmediatos del desastre fue la cancelación de clases en todos los niveles educativos, que a 10 días del evento distan mucho de regresar a la normalidad, sobre todo en la educación básica. Es entendible la preocupación de autoridades, padres de familia y de los propios estudiantes por la seguridad; pero es menester reflexionar sobre los múltiples efectos que esto conlleva: al no asistir los niños a la escuela, las madres y padres que trabajan se ven en la encrucijada afectiva, logística y financiera de qué hacer con ellos mientras tanto, ¿quién los cuidará?, ¿quién les dará el apoyo psicológico necesario?, ¿quién modulará las noticias del terremoto y sus consecuencias para que las entiendan en su justa dimensión?, ¿cómo cubrir el gasto extra en caso de que haya que pagar por su cuidado?, ¿cómo compensar la pérdida de muchos días de educación formal?, ¿quién les va a dar la “escuela en casa”? Todas estas preguntas y otras requieren respuestas inmediatas, y no siempre se obtiene el apoyo necesario, efectivo y expedito de las instituciones escolares, docentes, o se carece de un andamiaje familiar y de amistades adecuado. Todas las mamás que conozco están angustiadas en el trabajo, pensando cómo resolver estos retos y actuar en consecuencia, con los potenciales efectos en su desempeño laboral. Es momento de exhibir sensibilidad y compañerismo con nuestras colegas que se encuentran en esta situación, en el espacio de trabajo y en el entorno familiar, y que hagamos un esfuerzo porque esta actitud de soporte organizacional a las personas que tienen hijos se convierta en algo permanente.
En una exhibición de resiliencia impresionante, ciudadanos de todas las edades y todas las condiciones sociales, no sólo están saliendo adelante, sino que se están creciendo al reto. Los estudiantes adolescentes y adultos que se encuentran en los niveles de educación media y superior, nos han dado una gran lección con su actitud y sus acciones, ayudando con todas sus fuerzas, sin mirar a quién y sin esperar recompensa alguna sino la satisfacción de ayudar al prójimo. ¡Qué esta conducta permanezca y contagie a todos los estratos etarios!
Otro aspecto educativo a considerar, es ser testigos de cómo las vivencias intensas de este tipo generan un aprendizaje profundo y extremadamente significativo. A los que nos dedicamos a la docencia, lo que hemos atestiguado durante y después del temblor debe ponernos a pensar sobre la importancia relativa de la educación formal en el interior de las paredes institucionales. ¿Cuándo se aprende más, cuando se lee algo, se realiza un ejercicio de simulación artificial, o cuando se enfrenta un problema real que requiere soluciones inmediatas de consecuencias imprevistas? Estoy seguro que los médicos jóvenes, los estudiantes de pre y posgrado de ingeniería y arquitectura, entre muchos otros, aprendieron (y se transformaron) mucho más profundamente con esta experiencia que con cualquier ejercicio, tarea o solución de problemas en papel o en computadora. Por supuesto, no quiero decir que es mejor que haya desastres para que ocurra el aprendizaje, sino que este tipo de vivencias debe obligarnos a los docentes a poner los pies en la tierra y a no sobreestimar el efecto educativo de las experiencias curriculares excesivamente planeadas y microcontroladas, como nuestras conferencias tradicionales o los programas académicos de las asignaturas que en el papel se ven muy bien. Reflexionen aquellos que tengan responsabilidades docentes, ¿qué haremos con la disminución de días de clases en nuestro calendario académico, que se ha visto irremediablemente afectado por la catástrofe? La solución simplista de “reponer horas de clase” para “cubrir todo el programa”, sin tener en cuenta el contexto profundamente transformado de nuestra sociedad, no debe ser la respuesta predominante. Se requiere creatividad, innovación, trabajo en equipo y compromiso, tanto de docentes como de estudiantes, así como de las autoridades responsables de los centros educativos.
Una de las lecciones más importantes que nos deja el terremoto, es la importancia de la educación en la prevención, actuación debida durante y después de desastres mayores, para disminuir en lo posible los daños y las pérdidas humanas. Si uno de los factores que inciden en el aprendizaje es la repetición, la madre naturaleza se ha encargado de recordarnos, una y otra vez, lo importante que es poseer las habilidades y competencias para tener un desempeño adecuado al enfrentar desastres como un huracán o un terremoto, más allá del conocimiento teórico. Es curiosa la ausencia en el currículo formal de muchas de nuestras instituciones educativas, de la enseñanza y evaluación de las habilidades mínimas para confrontar este tipo de desastres naturales. Aunque en Internet y en la literatura científica existe una gran cantidad de recursos para aprender los conceptos básicos y avanzados sobre terremotos y otros desastres, frecuentemente no los revisamos hasta después del evento. Salimos debiéndole, en los hechos, a la cultura de prevención de la que tanto hablamos. En las pláticas de café en estos días (en las que es inevitable hablar del tema), todos nos hemos convertido en “expertos” en la escala de Richter, epicentros, diferencias entre oscilatorio y trepidatorio, Gales, la placa de Cocos, etcétera, ojalá este caudal de conocimientos permanezca y nos motive a profundizar en lo que realmente podemos hacer para tener respuestas más efectivas ante las catástrofes.
El cruel recordatorio de la naturaleza, que coincidió de manera inexplicable con el día 19 de septiembre, nos hizo rememorar vívidamente la experiencia que tuvimos en nuestra ciudad con el terremoto de 1985. Recordamos que también en esa época nos convertimos en “terremotólogos” de la noche a la mañana. A pesar de que muchas cosas se han hecho mejor en los últimos 32 años, aún nos falta muchísimo por realizar en el terreno educativo, creo que debemos “hacer de la necesidad virtud”. Incorporemos en nuestros currículos formales, vividos y ocultos los conceptos más relevantes para sobrevivir a los desastres y desaparezcámoslos del currículo nulo (concepto que se refiere a temas de estudio no enseñados, o que siendo parte del currículo no tienen aplicabilidad ni utilidad aparente, considerándose como contenido superfluo). Invito a los lectores a que tengamos en nuestras listas de “favoritos” recursos educativos confiables sobre estos temas, de los que existen muchos en la red (OMS, OPS, National Geographic, NEHRP, UNESCO). Existen también aplicaciones para dispositivos móviles que, utilizando videojuegos, pueden enseñar a tener conciencia sobre la importancia de estar preparado para situaciones de emergencia, un ejemplo es Tanah: contra los terremotos y tsunamis desarrollado por la UNESCO. Una de las fuentes de recursos más interesante sobre el tema es el International Network for Education in Emergencies (INEE), una red internacional de más de 13 000 miembros individuales y 130 organizaciones en 190 países. Los miembros de esta organización son personas interesadas en el tema (docentes, estudiantes, investigadores), organizaciones no gubernamentales, ministerios de educación y agencias de las Naciones Unidas que, de manera voluntaria, han unido esfuerzos para trabajar apoyando la educación durante emergencias (Shroder). Creo que vale la pena integrarse a este tipo de iniciativas, para que se sigan desarrollando e incrementen su capacidad de acción.
En conclusión, como han afirmado los expertos en el tema: “la educación ha sido clave para disminuir la mortalidad en los terremotos” (Knopoff).
“Científico de datos: codificando el valor oculto e intangible de los datos”. Uno de los cambios paradigmáticos más importantes del siglo XXI ha sido el advenimiento del concepto de Big data (volúmenes masivos de datos), y los sofisticados métodos analíticos utilizados para entender con precisión complejos fenómenos biológicos, físicos y sociales que antes eran imposibles de explorar. El artículo describe este fascinante campo y la nueva casta de científicos pionera en el área, los data scientists (científicos de datos), una combinación fascinante de pericia en diferentes disciplinas que rápidamente se está convirtiendo en una de las profesiones más solicitadas.
Sobre el tema que nos ocupa, el uso de Big data podría convertirse en uno de los “cambiadores de juego” en el escenario de predicción de los desastres. Estos días hemos oído en todos los noticieros y entrevistas a expertos, que es imposible predecir los terremotos y, en consecuencia, que tenemos que aprender a vivir en la incertidumbre (sabiendo que la Ciudad de México se encuentra en un área sísmica, y que tarde o temprano volveremos a repetir la experiencia vivida recientemente). Estas afirmaciones generalmente no tranquilizan mucho a la sociedad, aunque desde el punto de vista técnico parece ser que este tipo de fenómenos son inherentemente impredecibles (Marr, 2015). El uso de “terremoto” y “predicción” en la misma oración inmediatamente genera escepticismo, principalmente en la comunidad científica. El pronóstico de los terremotos es el “Santo Grial” de la sismología, y por muchas décadas ha sido buscado por los investigadores del área, sin éxito contundente (Marr, 2015 y 2016). Sin embargo, con el uso de la “magia” de la analítica de Big data, algunas organizaciones (http://www.terraseismic.com y otras) están utilizando los volúmenes masivos de datos generados de diversas fuentes (como los producidos por la red de satélites que circunda el planeta) para intentar predecir, con cierto grado de precisión, terremotos importantes que tengan potencial de causar daño (Singh y Haraksingh, 2016; Kannan, 2014; Sneed, 2017). Es importante señalar que aún no se ha resuelto el problema, que los académicos expertos en este tema recomiendan ser muy prudentes en la interpretación de la literatura (científica y de divulgación) que reporta estos interesantes hallazgos, y que no echemos las campanas al vuelo por artículos aislados o trabajos de empresas que tienen un conflicto de interés intrínseco al publicitar la efectividad de sus métodos e instrumentos. Sin embargo, el uso de métodos cada vez más sofisticados de inteligencia artificial y machine learning (aprendizaje de máquinas), podría ofrecer nuevos caminos para llegar a resolver este “acertijo imposible”.
Independientemente de lo lejos que estemos de tener un sistema de predicción de terremotos confiable, rápido y disponible para todos los países, creo que estos últimos eventos catastróficos deben ser una ruidosa alarma, un semáforo rojo, una llamada de atención impostergable a nuestros gobernantes, para que dediquen los recursos humanos y financieros que sean necesarios al desarrollo de la investigación científica. Ésta será la mejor manera de seguir avanzando en la prevención y detección temprana de los desastres naturales, en lugar del actual sentimiento de inevitabilidad y vulnerabilidad que prevalece. Por lo pronto, utilicemos los recursos globales que se han desarrollado, como los mapas de áreas afectadas por el terremoto proporcionadas por la NASA a las autoridades nacionales y a la comunidad en general, para ayudar a identificar las zonas dañadas en la Ciudad de México (disponibles en: https://www.jpl.nasa.gov/spaceimages/details.php?id=pia21963). El vaso de la tecnología no está totalmente lleno, pero tenemos la obligación moral de tener consciencia de estos recursos, ya que no utilizarlos se convierte en un desastre en sí mismo.
“Programa Adopte un Talento: un vínculo entre la comunidad científica y los niños”. Este artículo es extraordinariamente inspirador. No hay tarea más importante en la especie humana que la educación, ya que de ella se desprende todo lo positivo que podemos realizar en nuestro transitorio paso por el planeta. El programa PAUTA es una iniciativa innovadora, que pretende promover la inquietud científica en nuestro más preciado tesoro, la niñez mexicana. La metodología utilizada en el programa ha tenido resultados fascinantes, por lo que esperamos que en un futuro cercano haya iniciativas similares en otras instituciones. Debemos crear ese catalizador tan necesario en nuestro país: una comunidad científica competente, creativa, crítica, proactiva y propositiva, que contribuya a resolver los problemas ingentes de nuestra sociedad. Necesitamos más geólogos, sismólogos, paleosismólogos, divulgadores de la ciencia que expliquen con claridad estos fenómenos, y una sociedad dotada con las habilidades de pensamiento crítico suficientes para interpretar, cuestionar y aplicar los conocimientos generados por el gremio científico. La Universidad Nacional Autónoma de México, a través del Servicio Sismológico Nacional del Instituto de Geofísica, es el referente nacional en los temas de sismos, temblores y terremotos, es un hecho que debemos continuar impulsando su desarrollo e incrementando la red de instituciones nacionales e internacionales que son capaces de analizar y explicar estos fenómenos.
¿Procrastinar?, ¡no!
En este número de la revista aparecen también manuscritos de instituciones educativas, estudiantes y docentes, sobre los temas de la aplicación de las ciencias “ómicas”, las partículas subatómicas y las supercomputadoras, la experiencia digital de un educando y su impacto en la necesidad formativa, y la importancia de la formación tecnológica en la cultura científica. Invitamos a los lectores asiduos (¡y a los nuevos!) de nuestra publicación a explorar estos interesantes temas, no solo para incrementar su acervo cultural, sino para poner manos a la obra en la dura tarea de la recuperación de nuestro país. Con dolorosa frecuencia escuchamos que los mexicanos tenemos nuestra propia versión de “no dejes para mañana lo que puedas hacer hoy”, transformándolo en: “no hagas hoy lo que puedas hacer mañana”. Procrastinar es uno de los verbos que debemos intentar erradicar de nuestro léxico cotidiano nacional, para enfrentar con eficacia nuestras duras realidades.
Editor en Jefe
Melchor Sánchez Mendiola
Facultad de Medicina, UNAM
Referencias
INEE (International Network for Education in Emergencies). <http://www.ineesite.org/en/> (Accesado el 29 de septiembre de 2017).Kannan, S. (2014) Improving Innovative Mathematical Model for Earthquake Prediction. J Geol Geosci, 3:168. doi:10.4172/2329-6755.1000168 <https://www.omicsonline.org/open-access/improving-innovative-mathematical-model-for-earthquake-prediction-2329-6755.1000168.php?aid=28150>.
Knopoff, L. (1996). Earthquake prediction: the scientific challenge. Proceedings of the National Academy of Sciences of the United States of America, 93(9), 3719–3720. <https://www.ncbi.nlm.nih.gov/pmc/articles/PMC39427/>.
Marr, B. (2015). Big Data: Saving 13,000 Lives A Year By Predicting Earthquakes? Forbes. <https://www.forbes.com/sites/bernardmarr/2015/04/21/big-data-saving-13000-lives-a-year-by-predicting-earthquakes/#2a91cdb5d8da> (Accesado el 29 de septiembre de 2017).
Marr, B. (ed) (2016) Terra Seismic: Using Big Data to Predict Earthquakes, in Big Data in Practice: How 45 Successful Companies Used Big Data Analytics to Deliver Extraordinary Results, John Wiley & Sons, Ltd, Chichester, UK. doi:10.1002/9781119278825.ch39 <http://onlinelibrary.wiley.com/book/10.1002/9781119278825>
National Geographic. Education. Teaching resources. Eartquakes 101. <https://www.nationalgeographic.org/media/earthquakes-101-wbt/> (Accesado el 29 de septiembre de 2017).
National Earthquake Hazards Reduction Program. <http://www.nehrp.gov/> (Accesado el 29 de septiembre de 2017).
Organización Mundial de la Salud. Acción Sanitaria en las Crisis Humanitarias. Terremotos. <http://www.who.int/hac/techguidance/ems/earthquakes/es/> (Accesado el 29 de septiembre de 2017).
Organización Panamericana de la Salud. Departamento de Emergencias en Salud. <http://www.paho.org/disasters/?lang=es> (Accesado el 29 de septiembre de 2017).
Shroder, J. (2014). In Chile’s earthquake, education was key to low mortality. Understanding how to cope with megaquakes is essential for survival. Elsevier Connect. <https://www.elsevier.com/connect/in-chiles-earthquake-education-was-key-to-low-mortality> (Accesado el 29 de septiembre de 2017).
Singh, D., Haraksingh, I. (2016) Earthquakes can be Predicted. J Geol Geophys, 5:255. doi:10.4172/2381-8719.1000255 <https://www.omicsonline.org/peer-reviewed/earthquakes-can-be-predicted-79790.html>.
Sneed, A. (2017). Can Artificial Intelligence Predict Earthquakes? Scientific American <https://www.scientificamerican.com/article/can-artificial-intelligence-predict-earthquakes/> (Accesado el 29 de septiembre de 2017).
UNESCO. Educación en Contextos Emergencia. <http://www.unesco.org/new/es/quito/education/educacion-en-emergencia/guias-para-docentes/> (Accesado el 29 de septiembre de 2017).
UNESCO. Tanah. Aplicación contra terremotos y tsunamis. <http://www.unesco.org/new/es/quito/education/educacion-en-emergencia/tanah-contra-los-terremotos-y-tsunamis/> (Accesado el 29 de septiembre de 2017).
COMENTARIOS

Resumen
Este artículo aborda el significado y los alcances de la educación como un derecho humano, para lo cual se exponen algunos conceptos centrales como son los principios de los derechos humanos y las dimensiones del derecho a la educación. Desde ese paradigma, presenta un breve panorama de la educación obligatoria en México, y se centra en las condiciones escolares que, de acuerdo a una evaluación realizada por el Instituto Nacional para la Evaluación de la Educación (INEE) a fines de 2014, presentan las escuelas primarias del país. Se plantea como conclusión la necesidad de que todas las escuelas de México cuenten con un conjunto irreductible de condiciones que garanticen un mínimo de oportunidades de aprendizaje para todos los estudiantes.Palabras clave: derecho a la educación, condiciones escolares, escuelas primarias, desigualdad educativa.
How Right Is the Right to Education in México?
This article approaches the meaning and the reaches of education as a human right. For this purpose we will be touching central principles such as human rights and the right to educationon. From this paradigm we will present a brief panorama of obligatory education in México, focusing on elementary school conditions as stated in the 2014 Report on Education Evaluation by the National Institute for the Evaluation of Education. We propose as conclusion the need to enforce all Mexican schools have an irreducible set of conditions that guarantee a minimum of learning opportunities for all students.Keywords: right to education, school conditions, elementary schools, educational inequality.
La educación como un derecho humano

La reforma al artículo 3° constitucional, que se llevó a cabo en 2013, introdujo el reconocimiento de la educación de calidad como un derecho humano que, como tal, debe cumplir con los cuatro principios de los derechos humanos: universalidad, indivisibilidad, interdependencia y progresividad. Si bien este artículo no tiene la intención de profundizar en aspectos jurídicos, consideramos importante recordar brevemente su significado.
La universalidad se refiere a que, al ser inherentes al ser humano, los derechos deben garantizarse para todos, sin distinciones de ningún tipo (credo, etnia, ideología, género, etcétera), ya que todas las personas son iguales en dignidad y derechos; la indivisibilidad alude a que no pueden protegerse unos derechos y otros no, pues los derechos humanos son todos derechos, no pueden priorizarse o jerarquizarse; la interdependencia refiere a la relación que existe entre los derechos humanos, por lo que de afectarse uno, se impacta sobre otros derechos (en el caso de la educación, el cual se considera un derecho clave o habilitante (Latapí, 2009), su incumplimiento afecta el acceso a otros derechos como al trabajo, la alimentación, la salud y la vivienda); por último, la progresividad significa que cada vez deben ofrecerse más y mejores condiciones para el ejercicio de los derechos, y en ningún caso debe haber regresividad o reversibilidad.1

Visto así, el derecho a la educación es para todas las personas, independientemente de su contexto o condición, y con su cumplimiento deben protegerse también otros derechos. Como en cualquier derecho humano, es el Estado el responsable de promover, respetar, proteger y garantizar su cumplimiento, esto es, diseñar las políticas públicas y acciones para hacerlos efectivos.
¿Pero qué significa el derecho a la educación? El derecho a la educación no significa solamente el derecho a ir a la escuela –que es la institución del Estado mediante la cual se ofrece educación a la población– ya que si así fuera bastaría con que se dispusieran escuelas suficientes para todos. El derecho a la educación significa tanto el acceso a la escuela como su permanencia en ella y, sobre todo, el derecho a aprender y adquirir las competencias necesarias para que se alcancen las finalidades sociales de la educación. Esto implica que la educación debe tener ciertas características.

La primera relatora especial de las Naciones Unidas para el derecho a la educación, Katarina Tomasevski (2004), definió cuatro dimensiones del derecho a la educación, las cuales se conocen como el esquema de las 4 A: asequibilidad, accesibilidad, aceptabilidad y adaptabilidad. La asequibilidad se refiere a la disponibilidad de servicios educativos, que es el nivel más básico para garantizar el derecho a la educación; la accesibilidad significa el acceso efectivo a las escuelas, es decir, que no haya barreras de ningún tipo que impidan que alguien llegue y transite por la escuela; la aceptabilidad cualifica los servicios educativos, al señalar que éstos deben cumplir con determinados estándares de calidad (como maestros con formación adecuada, materiales educativos pertinentes, escuelas con infraestructura suficiente y que brinde seguridad a los estudiantes, etcétera); y, por último, la adaptabilidad, significa que los servicios educativos deben adaptarse a las características de la población y no al revés, es decir, tomar las medidas necesarias para atender con pertinencia a estudiantes migrantes, indígenas, a quienes no hablan la lengua de instrucción, a quienes presentan alguna discapacidad, etcétera.
Breve panorama del derecho a la educación en México
En México, la educación se ofrece en los siguientes tipos y niveles educativos.Esquema 1. Estructura del Sistema Educativo Nacional
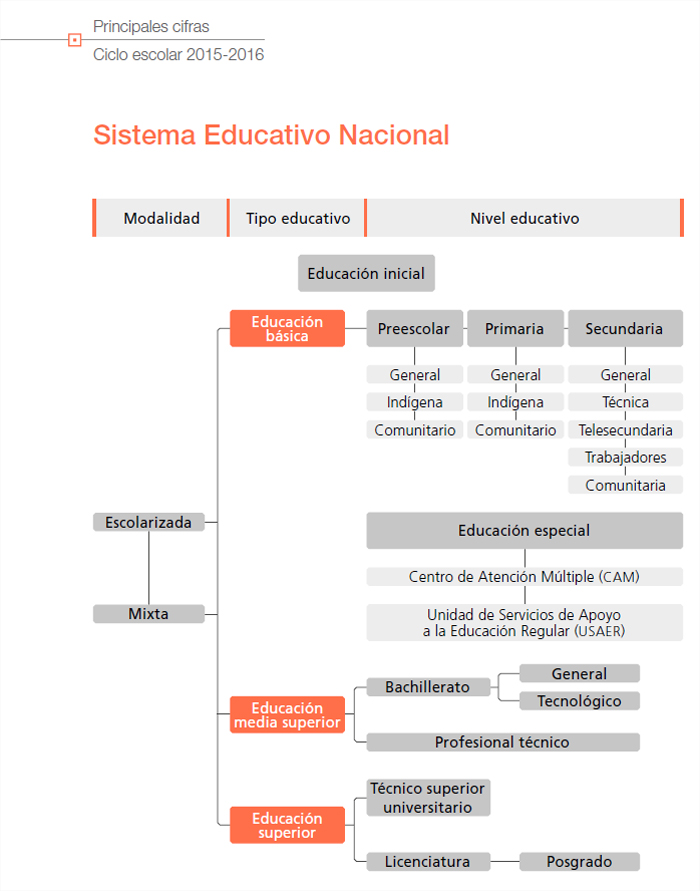
Fuente: INEE (2017a).

El sistema educativo mexicano es uno de los más grandes del mundo, con más de 30 millones de estudiantes, 1.5 millones de docentes y poco más de 240 mil escuelas o planteles en la educación obligatoria, esto es, en los tipos básico y medio superior2 (INEE, 2017a). Con estas cifras es posible ver que hemos avanzado en asequibilidad y accesibilidad de la educación obligatoria, sobre todo en educación básica. Las cifras más recientes disponibles (agosto de 2017), advierten que las tasas de matriculación3 a nivel nacional son superiores al 80% para los niños y niñas de 3 a 5 años, de 6 a 11 y de 12 a 14, y de 65% para los de 15 a 17 años; en estos grupos de edad el porcentaje de estudiantes que tiene un avance regular4 es superior a 92% (INEE, 2016a). Aunque los datos son alentadores, como es sabido, la menor cobertura educativa se tiene en las poblaciones en situación de vulnerabilidad social: migrantes, indígenas y personas con discapacidad.5
Donde, sin duda, tenemos los mayores retos –y que es en lo que se pretende enfocar lo que resta de este artículo–, es en la aceptabilidad y la adaptabilidad de la educación, es decir, en la forma como operan y funcionan las escuelas.
Condiciones escolares de las escuelas primarias6

Cuando hablamos de condiciones escolares probablemente pensamos en equipamiento como computadoras, pizarrones electrónicos, materiales multimedia y espacios escolares “de primera”: laboratorios equipados, biblioteca con acervos diversos, auditorios, canchas para practicar múltiples deportes; esto es porque consideramos que otras condiciones básicas “están dadas”. Pero probablemente sorprenda a muchos saber que la mitad de las escuelas primarias del país tienen menos de seis maestros, es decir, no hay maestros para atender en grupos separados a estudiantes de un mismo grado, es más, una de cada ocho escuelas primarias generales o indígenas del país sólo tienen un docente, que es el maestro de todos los estudiantes de los seis grados y además el director de la escuela –este último dato no considera las escuelas de modalidad comunitaria, que son en su gran mayoría unitarias– (INEE, 2016a).7

Otros datos que reflejan las condiciones en que operan las escuelas primarias en México son los siguientes: el 45% de las escuelas tiene los servicios básicos de agua, luz y drenaje; al 13.7% de escuelas les faltan aulas para atender a todos los grupos; el 18.7% no tiene tazas sanitarias para uso exclusivo de estudiantes. A uno de cada cuatro grupos de los últimos tres grados de primaria, les falta pizarrón en su salón de clases o el que tienen no funciona adecuadamente; poco más de un tercio de escuelas cuentan con libreros o estantes adecuados para guardar y exponer los materiales de la biblioteca escolar; en menos de una de cada cuatro escuelas hay acceso a internet para todos los miembros de la comunidad escolar; sólo uno de cada tres docentes que imparten la asignatura de lengua indígena, cuentan con el libro para el maestro de esa asignatura, y sólo en uno de cada cuatro grupos de estudiantes de 4°, 5° y 6° grado que cursaban esta asignatura los estudiantes recibieron el libro de texto (INEE, 2016c, 2016d y 2016e).8

Lo anterior ocurre porque no se han distribuido de la misma manera los recursos, porque contrario a un principio de equidad que llevaría a que el Estado ofreciera los mejores recursos a las poblaciones más desfavorecidas, ha tendido a concentrar las mejores condiciones en las zonas urbanas, donde en efecto hay más estudiantes, pero también es donde los niños y niñas tienen más oportunidades extraescolares para aprender. En cambio, en el campo, en las localidades pequeñas y dispersas y en las comunidades indígenas, es donde hay las mayores carencias educativas, incluso en algunas regiones no hay ni siquiera escuelas, por lo que los niños tienen que caminar diariamente a otras localidades para poder estudiar. Mostremos tres gráficas para apreciar estas diferencias.
Gráfica 1. Porcentaje de grupos de 4°, 5° y 6° de primaria donde todos los estudiantes tienen mueble en buenas o regulares condiciones para sentarse y escribir: nacional y por tipo de escuela
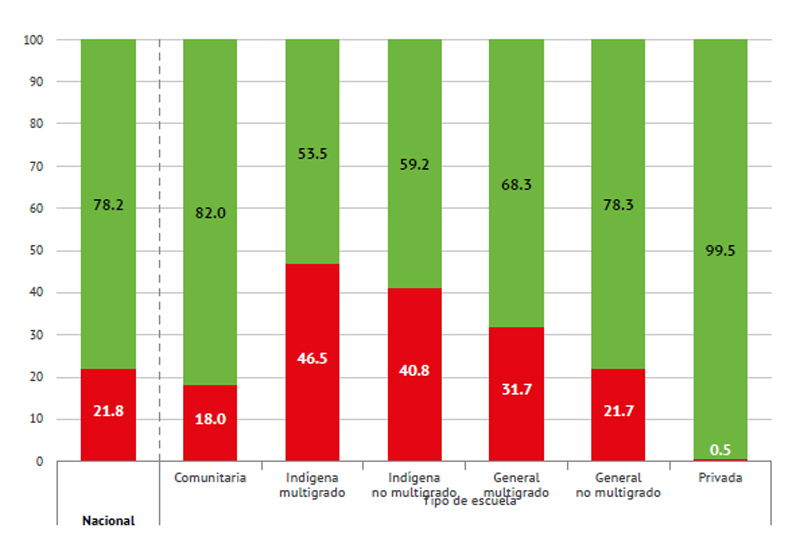
Fuente: INEE (2016c).
Informante: Docente/LEC.
Gráfica 2. Porcentaje de grupos de 4°, 5° y 6° de primaria según la proporción de estudiantes que cuenta con un juego completo de libros de texto: nacional y por tipo de escuela
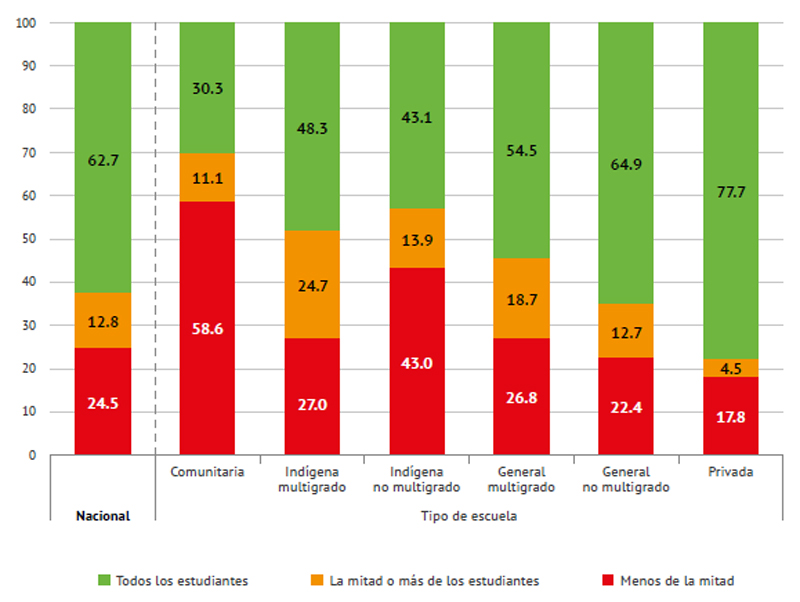
Fuente: INEE (2016c).
Informante: Docente/LEC.
Gráfica 3. Porcentaje de escuelas que reportaron estudiantes con discapacidad o necesidades educativas especiales y escuelas donde se informó que se cuenta con apoyo de personal especializado* para su atención: nacional y por tipo de escuela**
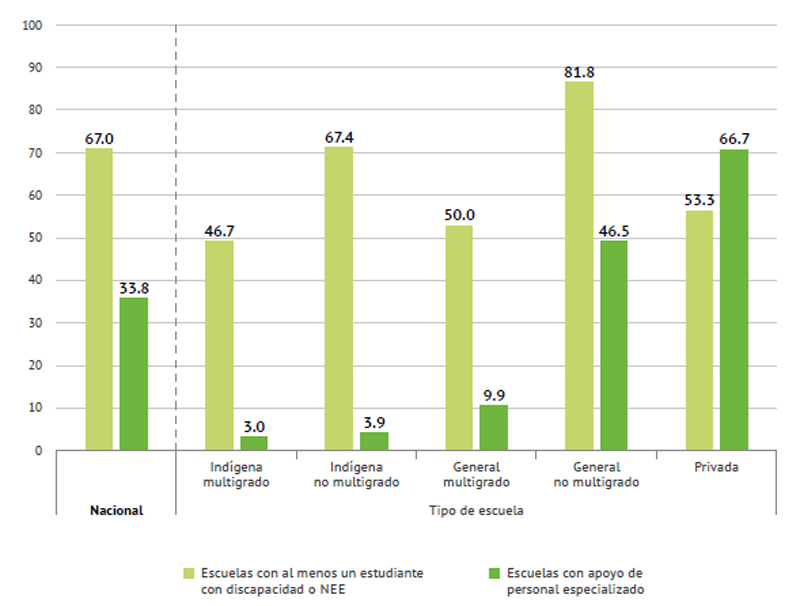
Fuente: INEE (2016c).
Informante: Director.
*Psicólogo, terapeuta de lenguaje, especialista en discapacidad, asesor pedagógico, apoyo de USAER.
**Se excluyen de la gráfica las escuelas comunitarias.
Las gráficas anteriores permiten notar que las mayores carencias de condiciones escolares están en las escuelas comunitarias, indígenas y generales multigrado, y que las brechas entre los distintos tipos de servicio son amplias, lo que muestra la manera tan desigual con que opera la educación en nuestro país.

Con la finalidad de orientar políticas educativas que aseguren un “piso mínimo común” de oportunidades educativas para todos los estudiantes del país, el Instituto Nacional para la Evaluación de la Educación (INEE) diseñó la Evaluación de condiciones básicas para la enseñanza y el aprendizaje (ECEA), la cual utiliza como referente un marco básico de condiciones sobre cómo y con qué deben funcionar mínimamente todas las escuelas en México, con base principalmente en lo que la misma normatividad y la política educativa establecen. Este marco básico está conformado por siete ámbitos y 21 dimensiones (ver tabla 1).
Tabla 1. Ámbitos y dimensiones que incluye la ECEA
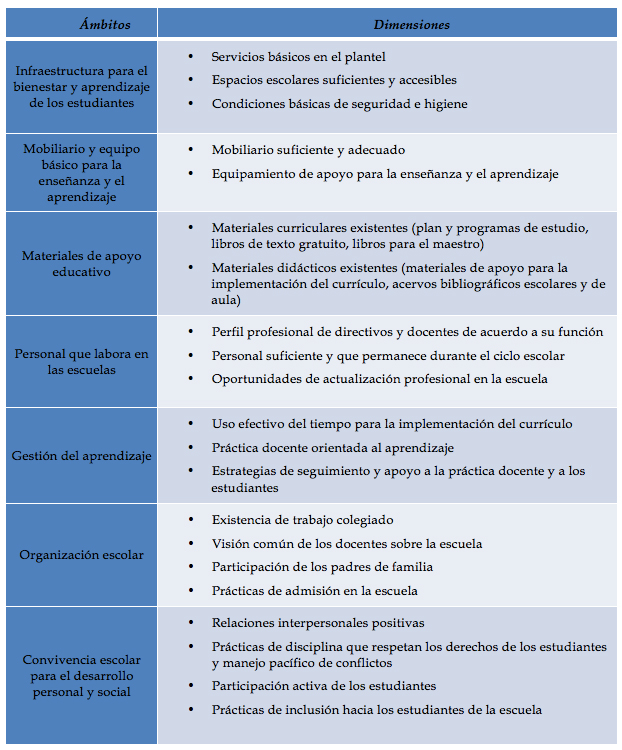
Una descripción muy sucinta de lo que evalúa la ECEA se puede encontrar en: http://www.inee.edu.mx/images/stories/2015/ecea2015/ECEA21201.pdf.

Los cuatro primeros ámbitos se refieren a recursos que, en el caso de las escuelas públicas del país, el Estado provee, es decir, corresponde a la autoridad educativa la responsabilidad de asegurar su cumplimiento. Los últimos tres ámbitos son procesos cuya responsabilidad principal recae en las propias comunidades escolares, aunque se reconoce que existe una interrelación entre ellos (por ejemplo, si la escuela no cuenta con espacios físicos para el trabajo colaborativo entre docentes, que es una condición de infraestructura, se afectará el trabajo colegiado, que alude a una condición de organización escolar). Al referirse a condiciones básicas o mínimas, el marco básico de la ECEA es indivisible, lo que significa que debe asegurarse el cumplimiento de todas y no sólo de algunas de las condiciones.
Si el lector quiere conocer más de esta evaluación lo invitamos a entrar al micrositio: http://www.inee.edu.mx/index.php/proyectos/ecea, así como ver este video:
Reflexiones finales
El derecho a la educación es más que el acceso y disponibilidad de servicios educativos; incluye la calidad de las condiciones y servicios con que se ofrecen. Ir a la escuela es necesario, pero no suficiente para el ejercicio pleno de este derecho, que implica en última instancia el derecho a aprender cosas relevantes para la vida.
En general en México, las escuelas en los contextos más pobres son las que tienen condiciones más precarias y ofrecen menor bienestar y oportunidades de aprendizaje a sus estudiantes; a estas escuelas no sólo no se les provee de mayores apoyos para subsanar las desventajas sociales, sino que ni siquiera se les da lo mismo que a otras ubicadas en contextos más favorables. Esto muestra la inequidad y la desigualdad en la oferta educativa.
Las escuelas deben ofrecer igualdad de oportunidades para todos los estudiantes, cuando menos deben asegurar condiciones básicas para funcionar. Las condiciones básicas son “irreductibles”, y por tanto necesarias para la enseñanza y el aprendizaje; por ello deben atenderse en conjunto y para todas las escuelas. De lo contrario el derecho a la educación seguirá siendo un privilegio de algunos y no un derecho de todos.
1 Existe múltiple literatura sobre este tema, en la bibliografía se incluyen dos referencias con acceso digital tanto para una lectura ligera sobre el tema (texto de la CNDH) como para una más especializada (Vázquez y Serrano, s/f).
2 En 2012 se declaró obligatoria la educación media superior en el país.
3 La tasa de matriculación es un indicador que se refiere al porcentaje de niños, niñas y adolescentes de cada grupo de edad que está matriculado en la escuela, independientemente del nivel educativo y grado.
4 El avance regular es un indicador que considera los niños, niñas y adolescentes matriculados en el grado escolar ideal de acuerdo a su edad o en uno inferior o uno superior.
5 Muestra de ello es que, en tanto a nivel nacional, la escolaridad de la población de 15 años y más es de 9.4 años, para ese mismo grupo de edad en la población jornalera agrícola migrante es de 4.5, para la población hablante de una lengua indígena de 5.7 y para las personas con discapacidad de 5.1 (INEE, 2016b, 2017b y 2017c).
6 El nivel educativo de primaria es el que tiene el mayor número de escuelas, docentes y estudiantes del sistema educativo mexicano.
7 Esto no necesariamente es así por insuficiencia de docentes, pero sí porque se anteponen criterios de eficiencia (número de estudiantes por docente) a los pedagógicos y de justicia social.
8 Para las poblaciones indígenas es un derecho humano recibir educación en su propia lengua.
Bibliografía
Meet the Dolls. Camry (2017). Naturally Perfect Dolls. Recuperado de <https://www.naturallyperfectdolls.com/pages/camryn>.
Comisión Nacional de Derechos Humanos (2016). Los principios de universalidad, interdependencia, indivisibilidad y progresividad de los derechos humanos. México: autor. Disponible en: <http://www.cndh.org.mx/sites/all/doc/cartillas/2015-2016/34-Principios-universalidad.pdf>.
INEE (2016a). Panorama Educativo de México 2015. Indicadores del Sistema Educativo Nacional. Educación básica y media superior. México: INEE. Disponible en: <http://publicaciones.inee.edu.mx/buscadorPub/P1/B/114/P1B114.pdf>.
INEE (2016b). Directrices para mejorar la atención educativa de niñas, niños y adolescentes de familias de jornaleros agrícolas migrantes. México: INEE. Disponible en: <http://publicaciones.inee.edu.mx/buscadorPub/P1/F/103/P1F103.pdf>.
INEE (2016c). Reporte general de resultados de la Evaluación de Condiciones Básicas para la Enseñanza y el Aprendizaje (ECEA) 2014 / Primaria. México: INEE. Disponible en: <http://www.inee.edu.mx/images/stories/2016/ecea/resultadosECEA-2014actualizacion.pdf>.
INEE (2016d). Infraestructura, mobiliario y materiales de apoyo educativo en las escuelas primarias. ECEA 2014. México: INEE. Disponible en: <http://publicaciones.inee.edu.mx/buscadorPub/P1/D/244/P1D244.pdf>.
INEE (2016e). La Educación Obligatoria en México. Informe 2016. Capítulo 2: Condiciones escolares para la enseñanza y el aprendizaje en la educación primaria. México: INEE. Disponible en: <http://publicaciones.inee.edu.mx/buscadorPub/P1/I/241/P1I241.pdf>.
INEE (2016f). Evaluación de Condiciones Básicas para la Enseñanza y el Aprendizaje desde la perspectiva de los derechos humanos. Documento conceptual y metodológico. México: INEE. Disponible en: <http://publicaciones.inee.edu.mx/buscadorPub/P1/E/201/P1E201.pdf>.
INEE (2017a). Principales cifras. Educación básica y media superior. Inicio del ciclo escolar 2015-2016. México: INEE. Disponible en: <http://publicaciones.inee.edu.mx/buscadorPub/P2/M/108/P2M108.pdf>.
INEE (2017b). La educación obligatoria en México. Informe 2017. Capítulo 3: Oportunidades educativas de niñas, niños y adolescentes con discapacidad. México: INEE. Disponible en: <http://publicaciones.inee.edu.mx/buscadorPub/P1/I/242/P1I242.pdf>.
INEE (2017c). Breve panorama educativo de la población indígena. Día Internacional de los Pueblos Indígenas. México: INEE. Disponible en: <http://publicaciones.inee.edu.mx/buscadorPub/P3/B/107/P3B107.pdf>.
Latapí, P. (2009). El derecho a la educación: su alcance, exigibilidad y relevancia para la política educativa. Revista Mexicana de Investigación Educativa, 14(40). Disponible en: <http://www.comie.org.mx/v1/revista/portal.php?idm=es&sec=SC03&&sub=SBB&criterio=ART40012>.
Tomasevski, K. (2004). Indicadores del derecho a la educación. Revista IIDH, 40. Disponible en: <https://revistas-colaboracion.juridicas.unam.mx/index.php/rev-instituto-interamericano-dh/article/view/8220/7368>.
Vázquez, L. D. y Serrano, S. (s/f). Los principios de universalidad, interdependencia, indivisibilidad y progresividad. Apuntes para su aplicación práctica. Disponible en: <https://archivos.juridicas.unam.mx/www/bjv/libros/7/3033/7.pdf>.
COMENTARIOS

Resumen
La ciencia de datos es una disciplina emergente y de gran pertinencia para todas las organizaciones que deseen codificar el valor oculto e intangible de sus datos. Hoy más que nunca estamos más conectados con personas y dispositivos, tenemos acceso a más redes y servicios, y sin duda consumimos y producimos mayores cantidades de datos e información. Por lo que requerimos contar con las habilidades, conocimientos, experiencias y técnicas de los científicos de datos para procesar, analizar y visualizar de formas más inteligentes los datos en información, promoviendo así, más y mejores conocimientos de nuestra realidad en sus contextos. En este artículo se explican las principales áreas en las que desarrolla un científico de datos (Big Data, minería y visualización de datos) y las intersecciones entre éstas; se incluyen ejemplos de proyectos desarrollados por científicos de datos y del gran valor que han sabido codificar. Además, se presenta una interpretación de los elementos que constituyen al científico de datos. Palabras clave: científico de datos + ciencia de datos + Big Data + minería de datos + visualización de datos.Data scientist: encoding the hidden and intangible value of the data
Data science is an emerging discipline of great relevance to all companies that wishing to encode the hidden and intangible value of data. Today more than ever we are connected to more people and devices, we have access to more networks and services, and not there are doubt that we consume and produce greater amounts of data and information. So we require the skills, knowledge, experiences and techniques of data scientists to process, analyze and visualize the data toward information in smarter ways, promoting more and better knowledge of their reality in their contexts. This article explains the main areas in which a data scientist develops (Big data, data mining and data visualization) and the intersections between these, including examples of projects developed by data scientists and the great value that they have known how to code it. In addition, to present an interpretation of the elements that constitute the scientific data. Keywords: data scientist + data science + Big Data + data mining + data visualization.Introducción
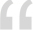 |
Las organizaciones deben saber aprovechar al máximo la información y explorar de manera inteligente cómo pueden beneficiarse del análisis de los datos que generan sus usuarios, operaciones, productos o servicios. | |
 |
||
Un mundo más conectado
Estamos en tiempos donde la conexión a múltiples sistemas de información es innegable, cada vez nos conectamos a más servicios y somos más dependientes de éstos. El paradigma ha cambiado en pocos años, tal como lo advierten Hilbert y Lopez (2011), hemos pasado de ser analógicos a ser digitales, lo que ha propiciado que estemos conectados desde diferentes dispositivos, a toda hora y desde cualquier lugar. Como resultado vivimos en un mundo cada vez más conectado, donde la inmediatez de la información se ha convertido en una necesidad de primer orden para hacer negocios, establecer relaciones sociales, consumir contenidos multimedia e incluso, estudiar en modalidades no tradicionales. La siguiente infografía hace un recuento del crecimiento que han tenido algunas de las principales aplicaciones y servicios en Internet en los tres últimos años. Nos ayuda a tener un referente de la magnitud de datos que llegan a manejar estas grandes compañías, por ejemplo: en 2016, YouTube reporta que en su plataforma cargan 500 horas de vídeo cada 60 segundos, por lo que al término del año suman 262.8 millones de horas de vídeo, es decir, para poder ver todo el contenido cargado en un año en YouTube se requerirían 30 000 años. Y los datos siguen creciendo año tras año.3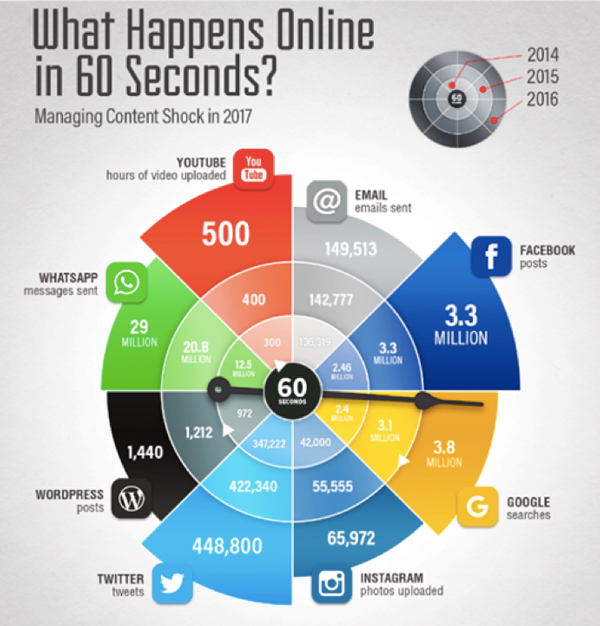 ¿Qué sucede en línea cada 60 segundos?
Fuente: Smart Insigts. Recuperado de: https://goo.gl/jiaDX2.
¿Qué sucede en línea cada 60 segundos?
Fuente: Smart Insigts. Recuperado de: https://goo.gl/jiaDX2. Interconexión de Facebook en el mundo.
Fuente: http://fbmap.bitaesthetics.com/.
Interconexión de Facebook en el mundo.
Fuente: http://fbmap.bitaesthetics.com/.El valor subestimado de los datos
Las compañías como Google, Facebook y Twitter gastan increíbles cantidades de dinero para mantener sus sistemas, sin embargo, los usuarios finales no son quienes pagan directamente esos gastos, en lugar de ello proveen contenido a la vez que son objeto de ambiciosas campañas publicitarias, lo que significa que otras compañías están pagando los costos de infraestructura a cambio de obtener datos de los usuarios (Van der Aalst, 2014). Para Twitter existen aplicaciones web donde se calcula el valor que tiene una cuenta, lo cual es un estimado con base al número de seguidores que tengas, la cantidad de personas que te siguen, los tweets que escribes y la velocidad con la que ganas seguidores. Por ejemplo, al hacer la prueba en los sitios twalue.com y tweetvalue.com reportaron que mi cuenta en Twitter (@jgmorenos) está valuada en $18.47 y $44 dólares, respectivamente. Recientemente el analista Cakmak (2017), analizó el valor que tiene para Twitter la cuenta de Donald Trump (37.4 millones de seguidores con más de 35 mil Tweets) y la calculó en 2 mil millones de dólares. Hay que considerar que estos valores son estimaciones y habrá que tomarlos con reserva, pero al menos son una invitación para reflexionar y no subestimar el valor que tienen los datos. Son varios los casos de éxito en donde las compañías se han beneficiado por codificar el valor oculto que tienen sus datos, para así mejorar sus productos y servicios, principalmente. Por ejemplo, Netflix ha sabido utilizar bien sus datos, pues tiene como objetivo principal: “ayudar a sus suscriptores a encontrar el contenido que realmente disfrutan, maximizando así su satisfacción y retención” (Elahi, 2015, p. 4). Desde sus inicios en 1997, con el servicio de renta y envío de DVD por correo postal, le dio una gran importancia a los datos de sus usuarios y en 2000 comenzó a desarrollar lo que sería su primer algoritmo (Cinematch) para crear un sistema que permitiera recomendar contenido de alto interés para cada uno de sus suscriptores. En el 2006, Netflix abrió su algoritmo a la comunidad científica y ofreció una recompensa de 1 millón de dólares para quién(es) lograran mejorar en un 10% su capacidad predictora, tuvieron que pasar tres años para que el grupo BellKor’s Pragmatic Chaos logrará resolverlo. En 2007 comenzó con su servicio de descarga y reproducción (streaming) de películas y series, y después de seis años lograron recopilar suficientes datos para predecir con seguridad el éxito de su primera producción original “House of Cards”. Éste es un claro ejemplo de cómo ser exitosos codificando datos y lograr que una serie obtenga alto interés de parte de los usuarios. El sitio statista.com reportó que en el segundo cuatrimestre de 2017 Netflix tiene 103.9 millones de suscriptores a nivel mundial, de los cuales procesa en promedio 695 mil millones de eventos por día, es decir, una base de datos de 1.8 Petabytes diarios.4 Algunos de los eventos registrados por Netflix son:Sin una gran cantidad de datos, no hubiera sido posible que Netflix siguiera entrenando sus sistemas de recomendación. Se necesita contar con una gran serie de datos históricos para poder analizar todas las posibles combinaciones, y así identificar patrones y tendencias que permitan tener algoritmos más robustos al momento de hacer las recomendaciones a sus suscriptores. Y tal como la misma compañía advierte “alrededor del 75% de la visualización en Netflix es impulsada por el algoritmo de recomendación” (Vanderbilt, 2013).
- ¿Desde dónde se conectan?
- ¿A través de qué dispositivo?
- ¿En qué horarios se conectan?
- ¿El tipo de contenido (película, serie) varia con el dispositivo?
- ¿Ven los créditos?
- ¿Cuánto tardan en ver el contenido?
- ¿Cuáles son sus actores y directores favoritos?
- ¿Qué y cómo califican?
- ¿Qué buscan?
- Etcétera.
Científico de datos
 Imagen: OpenClipart-Vectors.
El considerado padre del “management”, Peter Drucker (2004), reconoció que la sociedad postcapitalista es una sociedad basada en el conocimiento, donde el centro de la producción de la riqueza es el saber y no el capital. Los protagonistas claves en esta economía del conocimiento serán los “trabajadores del conocimiento”, es decir, los que posean las capacidades, las habilidades, el pensamiento creativo y la tecnología para procesar, analizar y visualizar las grandes bases de datos.
Los “trabajadores del conocimiento” que menciona Drucker, son los que ahora ya tienen un perfil más claro y se les conoce como científicos de datos, en ellos recae la responsabilidad de entender en su máxima expresión los datos y sus relaciones, con el objetivo de tomar decisiones más informadas a la vez que mejoran los productos y servicios de las organizaciones.
Davenport y Patil en su artículo “Data Scientist: The sexiest job of the 21st century” (2012), definieron por primera vez el concepto de científico de datos y con ello generaron una gran revolución. De acuerdo con las estadísticas obtenidas de scholar.google.com, el artículo ha sido citado 568 veces y se han producido 15 versiones diferentes. Además de definir quién es un científico de datos, presentan un decálogo para encontrar el científico de datos correcto, explican cuáles son los intereses del profesional y de los cuidados que deberán tener las empresas para conservarlos.
En términos generales, el científico de datos combina estadística, matemáticas, programación y solución de problemas, con la captura datos de forma ingeniosa y la capacidad de mirar las cosas de manera diferente (encontrar patrones), además de hacer las actividades propias de limpieza, preparación e integración de datos (Monnapa, 2017).
De acuerdo con la encuesta que realizó la compañía Crowd Flower (2017) a 179 científicos de datos seleccionados en todo el mundo, identificó la distribución de las actividades que les toma mayor tiempo en su quehacer, las cuales se distribuyen de la siguiente manera:
Imagen: OpenClipart-Vectors.
El considerado padre del “management”, Peter Drucker (2004), reconoció que la sociedad postcapitalista es una sociedad basada en el conocimiento, donde el centro de la producción de la riqueza es el saber y no el capital. Los protagonistas claves en esta economía del conocimiento serán los “trabajadores del conocimiento”, es decir, los que posean las capacidades, las habilidades, el pensamiento creativo y la tecnología para procesar, analizar y visualizar las grandes bases de datos.
Los “trabajadores del conocimiento” que menciona Drucker, son los que ahora ya tienen un perfil más claro y se les conoce como científicos de datos, en ellos recae la responsabilidad de entender en su máxima expresión los datos y sus relaciones, con el objetivo de tomar decisiones más informadas a la vez que mejoran los productos y servicios de las organizaciones.
Davenport y Patil en su artículo “Data Scientist: The sexiest job of the 21st century” (2012), definieron por primera vez el concepto de científico de datos y con ello generaron una gran revolución. De acuerdo con las estadísticas obtenidas de scholar.google.com, el artículo ha sido citado 568 veces y se han producido 15 versiones diferentes. Además de definir quién es un científico de datos, presentan un decálogo para encontrar el científico de datos correcto, explican cuáles son los intereses del profesional y de los cuidados que deberán tener las empresas para conservarlos.
En términos generales, el científico de datos combina estadística, matemáticas, programación y solución de problemas, con la captura datos de forma ingeniosa y la capacidad de mirar las cosas de manera diferente (encontrar patrones), además de hacer las actividades propias de limpieza, preparación e integración de datos (Monnapa, 2017).
De acuerdo con la encuesta que realizó la compañía Crowd Flower (2017) a 179 científicos de datos seleccionados en todo el mundo, identificó la distribución de las actividades que les toma mayor tiempo en su quehacer, las cuales se distribuyen de la siguiente manera:
Entre las actividades que más disfrutan, están: construir y modelar los datos, aplicar minería de datos para encontrar patrones y el refinar algoritmos. Entre las que menos gustan, están: limpiar y organizar datos, etiquetarlos y colectarlos. El 51% de los encuestados reportó que trabajan con datos no estructurados. Los datos con los que trabajan provienen principalmente de los sistemas internos de las compañías en las que trabajan, seguido de los que colectan de forma manual y, por último, de los conjuntos de datos disponibles públicamente. Son tres las áreas en las que se desarrollan principalmente los científicos de datos:
- 51% colectar, etiquetar, limpiar y organizar los datos.
- 19% construir y modelar los datos.
- 10% el modelado de datos para patrones.
- 9% refinar algoritmos.
- 8% otras actividades.
También existe una amplia gama de técnicas y software especializado que el científico de datos utiliza para desarrollarse en cada una de las áreas, de las cuáles se pueden clasificar por herramientas de extracción, almacenamiento, limpieza, minería, visualización, programación, análisis e integración de datos. En la siguiente figura se presentan las habilidades, los conocimientos y la experiencia que debe poseer el científico de datos, así como una muestra del software especializado y técnicas que existe por sus áreas de desarrollo.
- Big Data para procesar datos,
- Minería de datos para analizar e identificar relaciones ocultas, patrones y tendencias,
- Visualización de datos para explicar y socializar mejor la información obtenida.
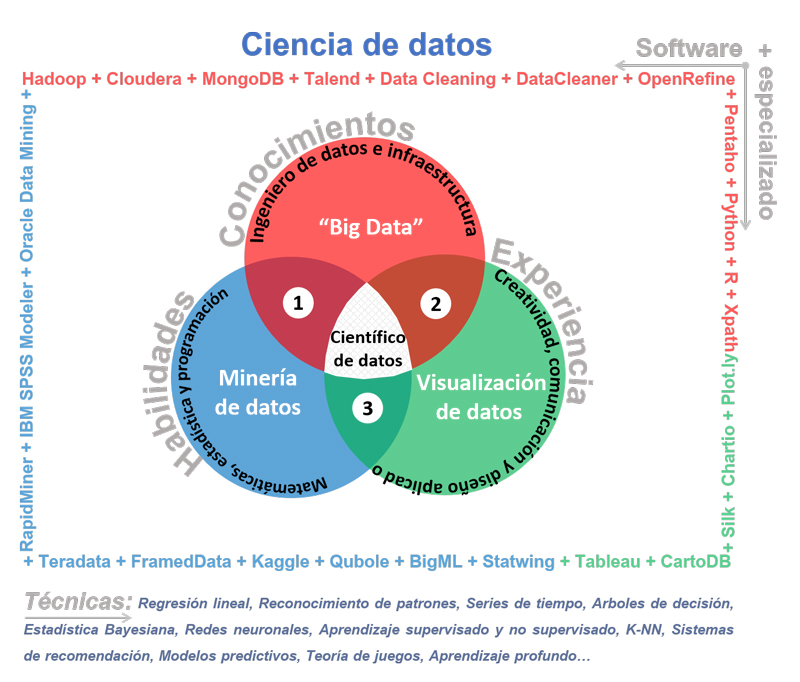 El científico de datos y su entorno.
Fuente: elaboración propia.
El científico de datos y su entorno.
Fuente: elaboración propia.Big Data
Los investigadores Cox y Ellsworth (1997) de la Administración Nacional de la Aeronáutica y del Espacio (NASA por sus siglas en inglés), fueron los primeros en utilizar el término Big Data en un artículo científico, en el que señalaron el problema al que se enfrentaban al visualizar y el procesar grandes cantidades datos, así como las limitantes técnicas de las computadoras (gráficos, memorias y almacenamiento) que tenían en esos tiempos. Ha sido un término que, al igual que su nombre, ha tenido una gran aceptación en todas las industrias y son muchas las definiciones que existen al respecto,5 en particular me gusta definir el concepto de Big Data como: el gran cúmulo de datos compuesto por diferentes tipos, estructuras y relaciones de datos, que a su vez tienen veloces tasas de generación y dispersión, y el procesarlos con tecnologías convencionales para su posterior análisis es parte del problema (Big Problem). De acuerdo con Van der Aalst (2014), utiliza el término Internet of Events (IoE) para referir a todos los datos disponibles en Internet. Y los clasifica de la siguiente manera:Es importante contar con este marco de referencia, ya que es una buena forma para clasificar la generación del Big Data por tipos de eventos.
- Internet of the Content (IoC). Es toda la información creada por los seres humanos para aumentar el conocimiento sobre temas particulares. Incluye páginas web tradicionales, artículos, enciclopedias como Wikipedia, YouTube, libros electrónicos, noticias, etcétera.
- Internet of the People (IoP). Son todos los datos relacionados con la interacción social. Es decir, correo electrónico, Facebook, Twitter, foros, LinkedIn, etcétera.
- Internet of the Things (IoT). Son todos los objetos físicos conectados a la red. Son todas las cosas que tienen una identificación única y una presencia en una estructura similar a Internet. Las cosas pueden tener una conexión a Internet o estar etiquetados usando identificación por radio frecuencia (RFID por sus siglas en inglés), proximidad a campos de comunicación (NFC por sus siglas en inglés), etcétera.
- Internet of the Locations (IoL). Refiere a todos los datos que tienen una dimensión espacial. Con la adopción de dispositivos móviles (por ejemplo, teléfonos inteligentes) cada vez más eventos tienen atributos geoespaciales.
Minería de datos
En términos sumamente prácticos la minería de datos la podemos definir como a la extracción de conocimientos de grandes cantidades de datos. Han y Kamber (2006), hacen una interesante crítica al concepto de minería de datos: “la extracción de oro de las rocas o la arena se conoce como minería de oro en lugar de minería de roca o arena. Por lo tanto, la minería de datos debería haber sido más apropiadamente llamada minería del conocimiento a partir de datos. Sin embargo, la minería es un término vívido que caracteriza al proceso de encontrar un pequeño conjunto de preciosas pepitas en una gran cantidad de materia prima” (p. 5). |
En términos sumamente prácticos la minería de datos la podemos definir como a la extracción de conocimientos de grandes cantidades de datos. | |
|
||
Visualización de datos
La visualización de datos es considerada por algunos como una ciencia y hay quienes la clasifican como un arte, cuando en realidad es una combinación de ambas. Sus principales precursores justo provienen de las ciencias exactas, que han tenido la necesidad de recurrir al campo de la creatividad y del arte, con el propósito de representar con fines estéticos algún aspecto de la realidad. Imagen: mcmurryjulie.
La visualización de datos sólo tendrá éxito en la medida que nuestros ojos codifiquen la información para poder discernirla y nuestros cerebros la pueden entender. El objetivo es traducir de maneras fáciles, eficientes, precisas y decodificadas la información abstracta en representaciones visuales significativas (Few, 2013).
La visualización de datos ayuda al usuario a examinar una gran cantidad de datos e identificar patrones o tendencias con la ayuda de gráficas o representaciones. Una sola gráfica puede codificar mucha más información que la que se puede presentar en varias hojas de texto (Pujari, 2001, p. 48).
La visualización de datos que ahora conocemos ha sido desarrollada a lo largo de la humanidad, siempre ha existido la necesidad de abstraer y comunicar información. Desde siglo II d. C. se han organizado los datos en tablas (columnas y filas), pero la idea de representar gráficamente la información cuantitativa surgió hasta el siglo XVII, cuando el filósofo y matemático francés René Descartes desarrolló un sistema de coordenadas bidimensional para mostrar valores. A finales del siglo XVIII, el ingeniero y economista William Playfair encontró el potencial de los gráficos para la comunicación de datos cuantitativos, definió muchos de los gráficos que se utilizan actualmente (barras y líneas en función del tiempo), incluso inventó el gráfico circular (pastel). Cabe señalar que este tipo de gráfico ha sido objeto de muchas críticas por parte de los especialistas en el área de visualización de datos y percepción. Por ejemplo, Few (2013) ha demostrado que es ineficaz, ya que codifica los valores como atributos visuales (áreas y ángulos), lo que impide percibir y comparar fácilmente.
El trabajo del cartógrafo Jacques Bertin fue fundamental, pues descubrió que la percepción visual opera según reglas que se pueden seguir para expresar visualmente la información de manera intuitiva, clara, precisa y eficiente. El profesor de estadística en Princeton, John W. Tukey,6 dio forma a un nuevo enfoque estadístico llamado análisis exploratorio de datos, y fue quien realmente introdujo el poder de la visualización de datos como un medio para explorar y dar sentido a los datos cuantitativos. El estadístico y artista Edward R. Tufte publicó en 1983 el libro The Visual Display of Quantitative Information, mismo que revolucionó las formas eficaces de mostrar los datos visualmente. El matemático William S. Cleveland con la publicación de sus libros The Elements of Graphing Data y Visualizing Data hizo grandes aportaciones en cuanto a las técnicas que utilizan los estadísticos para la visualización de datos. En 1999, los investigadores Stuart Card, Jock Mackinlay y Ben Shneiderman acuñaron una nueva especialidad “visualización de la información” y publicaron el libro Information Visualization, Using Vision to Think, en el que recopilan mucho del trabajo académico que se había realizado hasta ese momento, y a nuestros días es uno de los principales referentes de la visualización de datos e información (Few, 2013).
Actualmente el término visualización de datos es el más aceptado entre la comunidad científica de datos,7 pero en lo particular prefiero el término visualización de la información, ya que las actuales visualizaciones se hacen en al menos dos dimensiones con múltiples atributos y relaciones, por lo que no podemos estar hablando de visualización de datos, ya que de ser así se limitaría a mostrar numerosos elementos en una sola dimensión.
Imagen: mcmurryjulie.
La visualización de datos sólo tendrá éxito en la medida que nuestros ojos codifiquen la información para poder discernirla y nuestros cerebros la pueden entender. El objetivo es traducir de maneras fáciles, eficientes, precisas y decodificadas la información abstracta en representaciones visuales significativas (Few, 2013).
La visualización de datos ayuda al usuario a examinar una gran cantidad de datos e identificar patrones o tendencias con la ayuda de gráficas o representaciones. Una sola gráfica puede codificar mucha más información que la que se puede presentar en varias hojas de texto (Pujari, 2001, p. 48).
La visualización de datos que ahora conocemos ha sido desarrollada a lo largo de la humanidad, siempre ha existido la necesidad de abstraer y comunicar información. Desde siglo II d. C. se han organizado los datos en tablas (columnas y filas), pero la idea de representar gráficamente la información cuantitativa surgió hasta el siglo XVII, cuando el filósofo y matemático francés René Descartes desarrolló un sistema de coordenadas bidimensional para mostrar valores. A finales del siglo XVIII, el ingeniero y economista William Playfair encontró el potencial de los gráficos para la comunicación de datos cuantitativos, definió muchos de los gráficos que se utilizan actualmente (barras y líneas en función del tiempo), incluso inventó el gráfico circular (pastel). Cabe señalar que este tipo de gráfico ha sido objeto de muchas críticas por parte de los especialistas en el área de visualización de datos y percepción. Por ejemplo, Few (2013) ha demostrado que es ineficaz, ya que codifica los valores como atributos visuales (áreas y ángulos), lo que impide percibir y comparar fácilmente.
El trabajo del cartógrafo Jacques Bertin fue fundamental, pues descubrió que la percepción visual opera según reglas que se pueden seguir para expresar visualmente la información de manera intuitiva, clara, precisa y eficiente. El profesor de estadística en Princeton, John W. Tukey,6 dio forma a un nuevo enfoque estadístico llamado análisis exploratorio de datos, y fue quien realmente introdujo el poder de la visualización de datos como un medio para explorar y dar sentido a los datos cuantitativos. El estadístico y artista Edward R. Tufte publicó en 1983 el libro The Visual Display of Quantitative Information, mismo que revolucionó las formas eficaces de mostrar los datos visualmente. El matemático William S. Cleveland con la publicación de sus libros The Elements of Graphing Data y Visualizing Data hizo grandes aportaciones en cuanto a las técnicas que utilizan los estadísticos para la visualización de datos. En 1999, los investigadores Stuart Card, Jock Mackinlay y Ben Shneiderman acuñaron una nueva especialidad “visualización de la información” y publicaron el libro Information Visualization, Using Vision to Think, en el que recopilan mucho del trabajo académico que se había realizado hasta ese momento, y a nuestros días es uno de los principales referentes de la visualización de datos e información (Few, 2013).
Actualmente el término visualización de datos es el más aceptado entre la comunidad científica de datos,7 pero en lo particular prefiero el término visualización de la información, ya que las actuales visualizaciones se hacen en al menos dos dimensiones con múltiples atributos y relaciones, por lo que no podemos estar hablando de visualización de datos, ya que de ser así se limitaría a mostrar numerosos elementos en una sola dimensión.
Relación 1. Big Data y minería de datos
Debe existir una estrecha relación entre ambas áreas, ya que los algoritmos y modelos de entrenamiento y prueba desarrollados por el área de minería da datos deberán ser implementados en los grandes cúmulos de datos (Big Data), sobre todo cuando se tiene una amplia serie de datos históricos. Un ejemplo de lo anterior, es el artículo: “Applying Data Mining Techniques to Identify Success Factors in Students Enrolled in Distance Learning: A Case Study” (Moreno y Stephens, 2015). El artículo analiza, con técnicas de minería de datos, los perfiles de ingreso, antecedentes académicos y matrícula de los alumnos del Sistema Universidad Abierta y Educación a Distancia (SUAyED), de la Universidad Nacional Autónoma de México (UNAM), con el propósito de determinar los factores clave que impulsan el éxito y el fracaso de los alumnos, así como la creación de su respectivo modelo predictivo usando el algoritmo de clasificación Naive Bayes. Imagen: geralt.
Imagen: geralt.Relación 2. Big Data y visualización de datos
La relación entre el área de Big Data y la visualización de datos es la que busca definir la mejor interpretación y visualización de grandes cúmulos de datos y sus relaciones, de forma que al usuario le resulte más fácil entenderlos. En la mayoría de los casos se queda en la descripción de los datos en diferentes dimensiones y en algunos, incluyen interactividad a sus relaciones. A continuación, se presenta una muestra de ejemplos:
- Referencias cruzadas de la biblia (Harrison, 2007). Es un proyecto en el que se analiza, en la parte inferior de la visualización, todos los capítulos de la biblia en un gráfico de barras, los cuales alternan entre los colores blanco y gris claro. La longitud de cada barra denota el número de versos en el capítulo. Cada una de las 63 779 referencias encontradas en la biblia está representada por un solo arco y el color corresponde a la distancia entre los dos capítulos, creando un efecto similar al arco iris.
- Temperaturas del clima (Carli, 2013). Al superponer datos meteorológicos históricos, ésta visualización muestra cómo la temperatura evoluciona durante el año en diferentes ciudades. Al establecer una banda de zona de confort, es posible ver cuando la temperatura está por encima, dentro o debajo de la zona; tanto a lo largo del año como a través de los días de cada temporada. Es un claro ejemplo de una visualización interactiva.
- Población mundial (Carli, 2014). Es un proyecto de visualización interactiva realizado para el Banco Mundial donde cada usuario al digitar su fecha de nacimiento puede compararse con los datos de la población mundial (7.2 mil millones de personas al 2014), y saber cuántas personas nacieron el mismo día y a la misma hora. Al final presenta de manera ordenada la posición por la edad que tenga el usuario y la compara con la población mundial.
Relación 3. Minería de datos y visualización de datos
La minería y la visualización de datos también pueden trabajar en una dimensión donde no necesariamente se procesen un gran cúmulo de datos (Big Data), se pueden implementar proyectos para una cantidad mesurada de datos, donde se apliquen algoritmos y con éstos obtengamos un producto. A continuación, se muestran algunos ejemplos:
- FLEET: Distribución e Inventario de Unidades (Moreno, 2017a). Es un proyecto realizado para una empresa especializada al arrendamiento de vehículos, en el que se analiza el número de unidades que ha comprado por estado, municipio y concesionaria (agencia). Además, la visualización permite seleccionar los modelos de los vehículos, por segmento y rango de precios. Cabe señalar que todos los datos están relacionados y permiten la interacción.
- Gasolid: Identificador de Gasolineras en México (Moreno, 2017b). Es un proyecto que permite medir el nivel de confianza en las gasolineras mexicanas. Para lograrlo, se relacionaron bases de datos de la Procuraduría Federal del Consumidor (PROFECO) y Petróleos Mexicanos (PEMEX), además de correr procesos de geolocalización para identificar las direcciones de las estaciones de servicio. De acuerdo a la selección aplicada (estado, municipio y código de la estación de servicio), es posible ubicar a las gasolineras e identificar en nivel de confianza en éstas, así como el historial que ha tenido en los últimos cuatro años sobre el número de mangueras verificadas e inmovilizadas.
Relación 1, 2 y 3. Big Data, minería y visualización de datos
El científico de datos puede interactuar en cualquiera de las tres áreas (Big Data, minería y visualización de datos) y en sus respectivas intersecciones (1, 2 y 3), siempre y cuando posea las habilidades, conocimientos, técnicas y experiencia para lograr dar respuesta a las necesidades de las organizaciones en términos de codificar mejor sus datos. Drinking Data (Ratti, 2014). Es un proyecto que integra todas las áreas de la ciencia de datos y sus intersecciones, fue desarrollado por investigadores del Instituto Tecnológico de Massachusetts (MIT por sus siglas en inglés). La pregunta que detonó el desarrollo del proyecto fue: ¿podemos encontrar algún valor en la enorme cantidad de información registrada por las máquinas dispensadoras de refrescos enlatados? Considerando que en los Estados Unidos existen 15 000 máquinas dispensadoras y que cada una puede despachar 150 latas únicas. En cada transacción se registra una cadena de datos: hora, ubicación y preferencias del usuario (Big Data). Con éstos datos se visualizaron patrones de consumo total y se encontraron altos consumos de bebidas los fines de semana y lo contrario, durante los días entre semana (Visualización de datos). Con toda la explotación de los datos pudieron entender mejor lo que sucede: el analizar los dispensadores individualmente mostró características inesperadas (Minería de datos).Conclusiones
El inicio de la era Web 2.0 fue un momento crucial para las organizaciones que supieron beneficiarse de los datos que dejaban registrados los usuarios en sus plataformas (huella digital), por lo que hubo un incremento en la oferta de aplicaciones web –y sus respectivas versiones para teléfonos inteligentes–, ya que reconocieron el valor oculto e intangible que podían codificar de los datos de sus usuarios, tan sólo hay que recordar: “si no pagas por el producto, tú eres el producto” (Van der Aalst, 2014, p. 19). Imagen: JuralMin.
El sitio statista.com8 reportó, a marzo del 2017, que Google Play y Apple Store, administran 2.8 y 2.2 millones de aplicaciones, respectivamente. Por lo anterior, es que los científicos de datos se han convertido en especialistas de gran importancia para cualquier industria, ya que ofrecen servicios y productos hechos a la medida para cada uno de sus usuarios. La advertencia es: las compañías que no utilicen sus datos inteligentemente no serán competitivas y en el peor de los casos, no sobrevivirán.
Los científicos de datos se pueden especializar en cualquiera de las tres principales áreas (Big Data, minería de datos y visualización de datos), lo que ha propiciado que todas las industrias tengan una alta demanda por especialistas en estas áreas. IBM (2017) recientemente reportó que para el 2020 el número de empleos para todos los profesionales de datos en EUA aumentará en 364 mil, alcanzando un total de 2.7 millones de empleos.
El científico de datos viene a dar solución a las preguntas, ¿cómo almacenar los datos?, ¿cómo analizar y obtener valor de los datos? y ¿cómo visualizar y comunicar lo que nos quieren decir los datos? Todo lo anterior en términos de eficacia, eficiencia y veracidad. Por otro lado, Van der Aalst (2014), sugiere que el científico de datos responderá a las preguntas ¿qué paso?, ¿por qué paso?, ¿qué sucederá?, ¿qué es lo mejor que puede pasar?, las cuales, en mi opinión, sólo corresponden a el área de la minería de datos.
El Big Data ayuda a dar solución al gran problema que existe respecto al volumen, la variabilidad y la velocidad de los datos. El propósito de la minería de datos es pasar del volumen de datos hacia la información, para después el conocimiento y, por último, llegar al valor de la decisión.
Concluyo que debemos tener mucho cuidado con las diferentes visualizaciones de datos que ofrecen los diferentes softwares especializados, ya que existe el riesgo de hacer representaciones ineficaces de la información e incluso, nos podemos dejar llevar por gráficos muy elaborados presentados en diferentes dimensiones y que a simple vista parecen ser muy atractivos, cuando en la realidad dejan de lado la exploración y comunicación útil de la información y sólo presentan una estética superficial. La visualización no tiene límites, se puede representar cualquier tipo de dato con sus atributos, elementos y relaciones, todo dependerá de la creatividad para abstraer dicha información y presentarla de formas más inteligentes.
Imagen: JuralMin.
El sitio statista.com8 reportó, a marzo del 2017, que Google Play y Apple Store, administran 2.8 y 2.2 millones de aplicaciones, respectivamente. Por lo anterior, es que los científicos de datos se han convertido en especialistas de gran importancia para cualquier industria, ya que ofrecen servicios y productos hechos a la medida para cada uno de sus usuarios. La advertencia es: las compañías que no utilicen sus datos inteligentemente no serán competitivas y en el peor de los casos, no sobrevivirán.
Los científicos de datos se pueden especializar en cualquiera de las tres principales áreas (Big Data, minería de datos y visualización de datos), lo que ha propiciado que todas las industrias tengan una alta demanda por especialistas en estas áreas. IBM (2017) recientemente reportó que para el 2020 el número de empleos para todos los profesionales de datos en EUA aumentará en 364 mil, alcanzando un total de 2.7 millones de empleos.
El científico de datos viene a dar solución a las preguntas, ¿cómo almacenar los datos?, ¿cómo analizar y obtener valor de los datos? y ¿cómo visualizar y comunicar lo que nos quieren decir los datos? Todo lo anterior en términos de eficacia, eficiencia y veracidad. Por otro lado, Van der Aalst (2014), sugiere que el científico de datos responderá a las preguntas ¿qué paso?, ¿por qué paso?, ¿qué sucederá?, ¿qué es lo mejor que puede pasar?, las cuales, en mi opinión, sólo corresponden a el área de la minería de datos.
El Big Data ayuda a dar solución al gran problema que existe respecto al volumen, la variabilidad y la velocidad de los datos. El propósito de la minería de datos es pasar del volumen de datos hacia la información, para después el conocimiento y, por último, llegar al valor de la decisión.
Concluyo que debemos tener mucho cuidado con las diferentes visualizaciones de datos que ofrecen los diferentes softwares especializados, ya que existe el riesgo de hacer representaciones ineficaces de la información e incluso, nos podemos dejar llevar por gráficos muy elaborados presentados en diferentes dimensiones y que a simple vista parecen ser muy atractivos, cuando en la realidad dejan de lado la exploración y comunicación útil de la información y sólo presentan una estética superficial. La visualización no tiene límites, se puede representar cualquier tipo de dato con sus atributos, elementos y relaciones, todo dependerá de la creatividad para abstraer dicha información y presentarla de formas más inteligentes.
Bibliografía
Butler, P. (2010). Visualizing Friendships. Facebook: Facebook Enginering. Recuperado de <https://goo.gl/AaHLN>. Cakmak, J. (2017). What Is Trump Worth to Twitter? One Analyst Estimates $2 Billion. Fortune.com. Recuperado de <https://goo.gl/AdjDQz>. Carli, L. (2013). Weather Temperatures. Vis.design. Recuperado de <https://goo.gl/sgDNsS>. Carli, L. (2014). The World Population Project. Vis.design. Recuperado de <https://goo.gl/jSgpEx>. Cox, M. y Ellswort, D. (1997). Managing Big Data for Scientific Visualization. ResearchGate.net. Recuperado de <https://goo.gl/DLj8sd>. Crowd Flower (2017). Data Scientist Report 2017. Crowdflower.com. Recuperado de <https://goo.gl/4XsUKD>. Davenport, T. H. y Patil, D. J. (2012). Data Scientist: The Sexiest Job of the 21st Century. Harvard Business Review, 90 (10). Recuperado de <https://goo.gl/65IMw1>. Drucker, P. F. (2004). La sociedad postcapitalista. Medellín, Colombia: Norma Elahi, E. (2015). Spark and GraphX in the Netflix Recommender System. SlideShare. Recuperado de <https://goo.gl/LUQqx4>. Few, S. (2013). Data Visualization for Human Perception. En M. Soegaard (2nd Ed.), The Encyclopedia of Human-Computer Interaction. Aarhus, Denmark: The Interaction Design Foundation. Recuperado de: <https://goo.gl/7uYrrp>. Granville, V. (2016). 40 Techniques Used by Data Scientists. datasciencecentral.com. Recuperado de <https://goo.gl/UmCb9M>. Han, J. y Kamber, M. (2006). Data Mining Concepts and Techniques. Recuperado de <https://goo.gl/jmXNua>. Harrison, C. (2007). Bible Cross-References. Chrisharrison.net. Recuperado de <https://goo.gl/21DsY>. Hilbert, M. y Lopez, P. (2011). The world’s technological capacity to store, communicate, and compute information. Science, 332(6025), 60–65. IBM (2017). The Cuant Crunch: How the Demand for Data Science Skills is Disrupting the Job Market. Ibm.com. Recuperado de <https://goo.gl/yJ6GtL>. Monnappa, A. (2017). Data Science vs. Big Data vs. Data Analytics. Simplilearn.com. Recuperado de <https://goo.gl/EAYQRc>. Moreno, G. S., Stephens, C. R. (2015). Applying Data Mining Techniques to Identify Success Factors in Students Enrolled in Distance Learning: A Case Study. Advances in Artificial Intelligence and Its Applications: Springer. Recuperado de <https://goo.gl/zFLHtJ>. Moreno, G. S. (2017a). FLEET: Distribución e Inventario de Unidades. Publictableau.com. Recuperado de <https://goo.gl/Db5eXr>. Moreno, G. S. (2017b). Gasolid: Identificador de Gasolineras en México. Publictableau.com. Recuperado de <https://goo.gl/26iX9C>. Pujari, A. K. (2001). Data Mining Techniques. Hyderabad, India: Universities Press. Ratti, C. (2014). Drinking Data. senseable.mit.edu: MIT Senseable City Lab. Recuperado de <https://goo.gl/QkJ4iw>. Shapiro, G. P., Smyth P. (1996). The KDD Process for Extracting Useful Knowledge from Volumes of Data. Communications of the ACM. Volumen (39, 11), 27-34. Recuperado de <https://goo.gl/L67PYa>. Van der Aalst, W. M. P. (2014). Data Scientist: The Engineer of the Future. Enterprise Interoperability, volume 7, 13-28. Springer. Recuperado de <https://goo.gl/yiaE9F>. Vanderbilt, T. (2013). The Science Behind the Netflix Algorithms That Decide What You’ll Watch Next. Wired. Recuperado de <https://goo.gl/aqJqA7>. Wirth, R., Hipp, J. (2000). CRISP-DM: Towards a Standard Process Model for Data Mining. ResearchGate.com. Recuperado de <https://goo.gl/XevGEB>.
COMENTARIOS
Resumen
Las “ómicas” son las ciencias que permiten estudiar un gran número de moléculas, implicadas en el funcionamiento de un organismo. En las últimas décadas, el avance tecnológico ha permitido el estudio a gran escala de muchos genes, proteínas y metabolitos, permitiendo la creación de la genómica, proteómica, metabolómica, entre otras. Cada una de estas áreas ha ayudado a un mejor entendimiento de la causa de ciertas enfermedades. Además, la aplicación del conocimiento sobre las “ómicas” a la clínica podrá utilizarse para hacer un diagnóstico más temprano o para prevenir el desarrollo de una enfermedad. Así, la medicina se podrá convertir en medicina personalizada, donde cada individuo llevará un tratamiento para una determinada enfermedad acorde a su información genética y a su medio ambiente. En este artículo se define a cada una de las “ómicas”, la metodología que se usa para su análisis y un ejemplo de su aplicación clínica.Palabras clave: ácido desoxirribonucleico (ADN), ácido ribonucleico (ARN), proteínas, metabolitos, ciencias “ómicas”.
The “omics” sciences, how does this help health sciences?
“Omics” are defined as a group of disciplines that aim to collect a large number of biological molecules involved in the function of an organism. In the last decades, technological evolution allowed us to better understand global changes in genes, proteins and metabolites, giving rise to genomics, proteomics, metabolomics, among others. These fields have contributed to the generation of knowledge regarding the cause of diseases. The application of the “omics” to the clinics could help diagnose or prevent certain diseases. In the future, treatment will be specific for each patient according to their genetical background and environment exposure, creating personalized medicine. This article defines every –omic, the technological tools used for its analysis, and examples of its clinical applications.Keywords: DNA (deoxyribonucleic acid), RNA (ribonucleic acid), proteins, metabolites, “omics” sciences.
Introducción
Historia del ADN
 |
El ADN está formado por la unión de nucleótidos formados por bases nitrogenadas (adenina, guanina, citosina, timina), un azúcar (desoxirribosa) y ácido fosfórico. La combinación de estos nucléotidos da origen a los genes, los cuales guardan la información genética. | |
 |
||
En 1944, Oswald Avery, Colin MacLeod y MacLyn McCarty descubrieron que el ADN es el “principio de transformación” o material genético (Avery, MacLeod y McCarty, 1944). Sin embargo, la comunidad científica de aquella época exigía más información sobre dicho material genético, por lo cual, diversos investigadores continuaron en la búsqueda de pruebas y fueron Alfred Hershey y Martha Chase (1952) quienes demostraron definitivamente que el ADN es la molécula que guarda la información genética heredable. Posteriormente, en 1953, Watson y Crick describieron la estructura del ADN, la cual está formada por dos cadenas complementarias que se unen en direcciones inversas (1953). Sin embargo, fue hasta 1977, que se logró decodificar o secuenciar por primera vez el ADN, lo cual quiere decir que se estableció el orden de los nucléotidos de un fragmento de ADN. Esto asentó los fundamentos para el análisis y secuenciación del genoma. Sin embargo, debido al desarrollo científico y tecnológico que se logró en los años siguientes, fue que en 2001 se logró secuenciar el genoma humano (Venter et al., 2001).
Dogma central de la biología molecular
Se conoce como el dogma central de la biología molecular a la forma como fluye la información genética del ADN, desde su paso por el ácido ribonucleico mensajero (ARNm) y hasta llegar a las proteínas.El ADN está formado por la unión de nucleótidos formados por bases nitrogenadas (adenina, guanina, citosina, timina), un azúcar (desoxirribosa) y ácido fosfórico. La combinación de estos nucléotidos da origen a los genes, los cuales guardan la información genética. A partir de los genes, se lleva a cabo la transcripción, mecanismo por el cual el ADN se convierte a ARNm. Finalmente, la traducción permitirá que el ARNm se convierta en una proteína.
Por lo tanto, se puede decir que el ADN es un archivero en el que se guarda toda la información. El ARNm es el mensajero que lleva la información del archivero a donde se va a utilizar. Finalmente, esa información es utilizada por los obreros, correspondientes a las proteínas (véase figura 1). Cabe mencionar que el ADN se replica para que a partir de una célula madre, se generen dos células hijas conteniendo el mismo material genético.
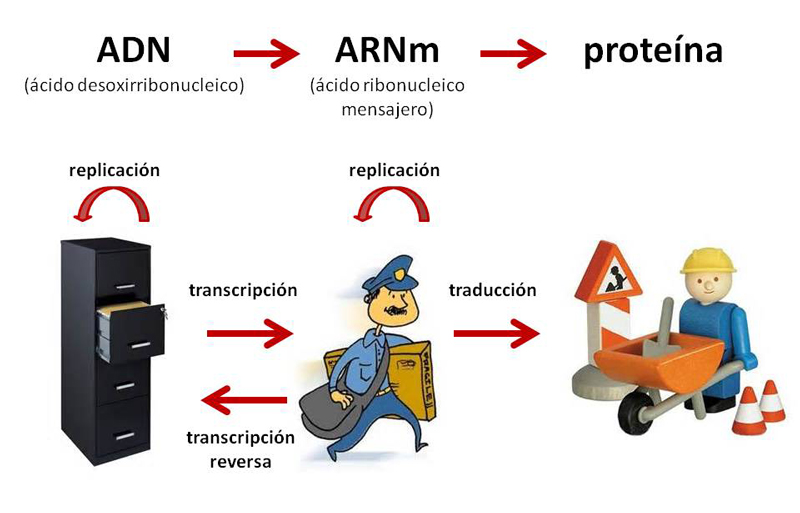
Figura 1. El ADN es como un archivero que contiene la información que el mensajero distribuye para que se lleve a cabo la síntesis de proteínas (o que actúe el obrero).
Un gen es un fragmento de ADN que contiene la información genética. Las regiones que separan a los diferentes genes se llaman regiones intergénicas. Un gen está conformado por diversas partes como el promotor, exones e intrones, principalmente. El promotor es la secuencia del gen que es reconocida por la maquinaria de transcripción para convertir el ADN a ARNm. Los exones son las secuencias del ADN que dan origen a la proteína. Estos exones pueden estar interrumpidos por los intrones, que son regiones que pueden regular la transcripción de los genes. El ARNm maduro sólo estará formado por la secuencia de los exones, la cual va a ser traducida para sintetizar una proteína (véase figura 2).

Figura 2. Los exones se traducen para sintetizar las proteínas.
El ADN se encuentra en todos los núcleos de las células del organismo y es exactamente el mismo, por lo que, se puede extraer ADN de la sangre, cabello, saliva o cualquier célula, obteniendo la misma información genética. Sin embargo, el ARNm es diferente, ya que a partir del ADN que tienen todas las células, se transcribe solamente el ARNm que necesita una célula determinada, para posteriormente ser traducido a la proteína que ejercerá la función en dicha célula. Por lo tanto, el ARNm y las proteínas son dinámicas y son específicas de tiempo, tratamientos y de células.
El ADN del humano está formado por tres billones de nucleótidos que contiene alrededor de 30 000 a 40 000 genes, donde entre 1 y 2% del genoma son regiones codificantes y el resto no codifican para una proteína, pero regulan la presencia del ARNm o expresión de los genes (Harrow et al., 2012).
“Ómicas”: generalidades de análisis de muchos datos
En los últimos años ha existido un gran avance en el desarrollo de la tecnología, lo cual ha provocado que se generen equipos analíticos que logran identificar y medir muchas moléculas. Esto ha ido de la mano con la creación de grandes computadoras, que permiten el almacenamiento de gran cantidad de información, de igual manera, el desarrollo de software ayuda al análisis de los datos generados. Todo esto ha dado como resultado el análisis de diferentes moléculas (ADN, ARN, proteínas, etcétera) y la creación de redes de interacción entre ellas para comprender con más exactitud a los sistemas biológicos complejos.En los años 1980, el término “ómica” se acuñó para referirse al estudio de un conjunto de moléculas. Por ejemplo, genómica se refiere al estudio de muchos genes en el ADN; transcriptómica es el estudio de muchos transcritos o ARNm; proteómica es el estudio de muchas proteínas; metabolómica es el estudio de muchos metabolitos, entre otros.1
Antes, los químicos y biólogos realizaban la parte experimental de su investigación y análisis de una o pocas moléculas que se podían estudiar en laboratorios. Gracias al avance de la tecnología y de las herramientas de análisis, se incrementó el número de moléculas detectables al mismo tiempo, por lo que se han formado grupos multidisciplinarios constituidos por biólogos, químicos, médicos, programadores, bioinformáticos, bioestadísticos, que juntos colaboran para la interpretación de todos los datos recabados.
Al aumentar el número de moléculas a analizar fue necesario acrecentar también el tamaño de muestra para mantener un poder estadístico válido. Es por esto que se crearon biobancos tales como el de UK Biobank (biobanco del Reino Unido), para el cual se reclutaron a 500 000 individuos y se tomaron muestras de sangre, orina y saliva para su análisis posterior. Este tipo de biobancos ayudará a las diversas disciplinas “ómicas” en su estudio de las enfermedades para mejorar el diagnóstico, prevención y tratamiento de las mismas.
A continuación, se describe brevemente lo que estudia cada “ómica”, así como la metodología empleada para su análisis y alguna aplicación en la clínica. Es importante hacer notar que los datos que se obtienen de cada una no nos permiten conocer completamente un sistema biológico. Sólo la integración de varias de éstas y la relación que existe entre ellas, nos es útil para conocer globalmente a dichos sistemas.
Genómica
La genómica fue la primera “ómica” en crearse, esta ciencia se encarga del estudio del genoma o ADN. Anteriormente, la tecnología permitía estudiar pocos genes, así como sus cambios o mutaciones, a lo que se le denominaba genética. Sin embargo, la tecnología avanzó y a principios del siglo XXI se reportó la secuencia del genoma humano (Venter et al., 2001), lo que quiere decir que se descifró el orden de todos los nucleótidos contenidos en el ADN del humano (International Human Genome Sequencing Consortium, 2004). La secuencia del genoma reveló que 99% del genoma entre humanos es el mismo y sólo 1% es diferente. Estas diferencias son llamadas variantes de un solo nucleótido (SNV por sus siglas en inglés), anteriormente llamados polimorfismos de un solo nucleótido o SNP (véase figura 3). Estas variantes son frecuentes y confieren susceptibilidad o protección para desarrollar enfermedades.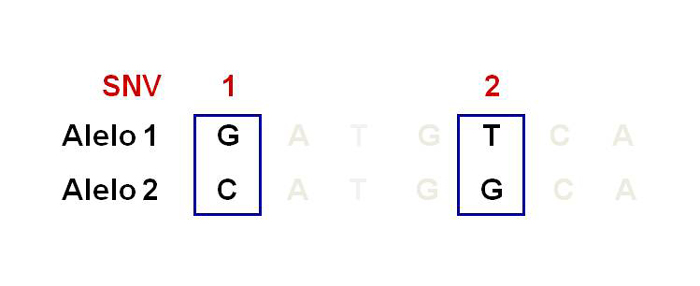
Figura 3. Polimorfismos de un solo nucleótido.
Anteriormente, se estudiaban fragmentos de ADN y su localización en los diferentes cromosomas por medio de metodologías de hibridación in situ con fluorescencia (FISH). De esta forma era posible señalar cierto fragmento del ADN, conteniendo uno o varios genes, el cual era el causante de una enfermedad, debido a la depleción, duplicación, inversión y translocación cromosómica de dicho fragmento de ADN. Posteriormente, surgió la secuenciación con el método Sanger que consiste en replicar la región del genoma de interés por medio de cebadores específicos y utiliza dideoxinucleótidos marcados radioactivamente que posteriormente evolucionaron a marcaje fluorescente. Estos nucleótidos marcados al ser incorporados en la nueva cadena amplificada, finalizarían la reacción permitiendo conocer el último nucleótido de dicha reacción y establecer la secuencia del ADN. Esta metodología se desarrolló en los la década de 1970 y se acopló a estrategias de secuenciación a gran escala, lo que permitió realizar la secuenciación del genoma humano en 2001; sin embargo, estas metodologías eran muy costosas.
El avance de la tecnología ha permitido crear nuevos métodos para reducir costos y obtener secuenciaciones masivas, creando la “secuenciación de siguiente generación”, volviendo más accesible su uso. En la actualidad es posible elegir qué regiones del genoma se desean secuenciar. Por ejemplo, a partir del ADN de un individuo se puede secuenciar el genoma completo, solo exones o regiones específicas del genoma (genes), con la finalidad de encontrar la región del genoma que pudiera estar afectada o mutada y ser la posible causante de alguna enfermedad.
Por otra parte, el descubrimiento de las variantes de un solo nucleótido originó que se desarrollaran otras metodologías para su identificación, como la llamada genotipificación. La genotipificación consiste en amplificar el ADN y añadir a la reacción una sonda (fragmento de 25 nucleótidos) que se pueda hibridar o unir a la variante de nuestro interés y así obtener el genotipo del individuo.
|
[…] el término “ómica” se acuñó para referirse al estudio de un conjunto de moléculas. | |
|
||
Por otra parte, la genética ha ayudado a describir enfermedades que son heredables con un patrón mendeliano, las cuales generalmente contienen mutaciones (poco frecuentes) en la parte que codifica un gen, provocando que haya un cambio funcional de la proteína y que se presente la enfermedad (por ejemplo, fibrosis quística). Sin embargo, hay enfermedades que no siguen el patrón mendeliano y se les conoce como enfermedades comunes. Es aquí donde la genómica ha permitido describir muchas variantes que están asociadas a alguna enfermedad, por ejemplo: obesidad y diabetes. Las variantes asociadas a enfermedades comunes son frecuentes (a diferencia de las mutaciones) y se presentan en regiones regulatorias de los genes y conceden susceptibilidad o protección para el desarrollo de la enfermedad.
Imagen: kropekk_pl. Existen algunas limitantes de los estudios genómicos como son las siguientes: primero, las variantes asociadas a una enfermedad explican solamente una pequeña parte del componente heredable; en segundo lugar, las variantes pueden ser reguladas por factores ambientales independientemente de la secuencia del ADN (ver epigenómica). Es por esto que la genómica ofrece correlaciones entre las enfermedades y las variantes génicas, sin demostrar cómo esa variable puede ser causal de la enfermedad. Entonces, es necesario integrar estas correlaciones con otras “ómicas” para encontrar la función de los genes y de las variantes que los modulan, para comprender mejor la causa de la enfermedad.
Transcriptómica
El ADN se transcribe a ARNm y a éste le llamamos también transcrito. La transcriptómica es la “ómica” que se encarga de estudiar la expresión de los transcritos que provienen de diferentes genes. El ARNm es específico de cada célula y de las condiciones fisiopatológicas en determinado momento. Por ejemplo, el ARNm extraído de células del músculo será diferente a las células del hígado antes y después de comer. Es por esto que la transcriptómica se hace en tejido y en tiempo específico, ya que la transcripción es muy dinámica.Anteriormente, se creía que gran parte del ADN que no se transcribía a ARNm, no tenía ninguna función y se consideraba ADN “basura.” Sin embargo, además del ARNm existen otros transcritos no codificantes como son: 1) los miRNA (micro ARN, secuencias de 21-25 nucleótidos) y, 2) los lncRNA (ARN largos no codificantes, >200). Estos tipos de transcritos no codificantes tienen como función regular la expresión de los ARNm codificantes. Por lo tanto, sabemos en la actualidad que estas regiones del ADN son secuencias reguladoras de la expresión de diversos genes y no son “basura”.
Las metodologías que se utilizan para analizar el ARNm son: 1) microarreglos o 2) secuenciación del ARN (RNAseq por sus siglas en inglés). Los microarreglos consisten en hibridar el ARNm de un determinado tejido a secuencias de genes previamente conocidos que se encuentran unidas a un microarreglo. De esta forma, se pueden hacer comparaciones entre casos o controles o simplemente ver qué genes se expresan mayoritariamente en ciertas condiciones. En cambio, el RNAseq consiste en secuenciar todos los transcritos presentes en esas condiciones, teniendo como consecuencia encontrar nuevos transcritos que no se conocían anteriormente y nuevos genes involucrados en un padecimiento.
En la actualidad, una de las aplicaciones de la transcriptómica es el análisis de la expresión de genes implicados en diferentes tipos de cánceres. Por ejemplo, en México se ha utilizado el microarreglo Oncotype RX, el cual mide la expresión de 21 genes involucrados en el cáncer de mama, para mejorar la toma de decisiones del tratamiento por parte del clínico tratante. Los resultados mostraron que al aislar el ARNm de una biopsia del tumor de mama e hibridándolo al microarreglo aumentó la expectativa de vida de los pacientes y redujo los costos de la enfermedad (Bargalló-Rocha et al., 2015).
Proteómica
El ARNm es traducido a proteínas (formadas por aminoácidos), las cuales están encargadas de realizar la función correspondiente del gen. La proteómica se encarga de estudiar muchas proteínas presentes en una muestra.Una vez que las proteínas son traducidas pueden sufrir modificaciones post-traduccionales, tales como cortes, fosforilación, glucosilación, sumolización. Estas modificaciones provocan cambios estructurales que controlan la formación de complejos funcionales proteicos, regulan la actividad de las proteínas y las transforman en formas activas o inactivas. Algunos de estos cambios son señales para la estabilidad o degradación de las proteínas. La proteómica estudia a las proteínas, así como las modificaciones post-transcripcionales que las regulan. Al igual que el ARNm, las proteínas se expresan en tejido y tiempo específico, por lo que la toma de la muestra dependerá del tejido y del estadio de la fase celular de interés.
La metodología para estudiar la proteómica consiste principalmente en: 1) separar las proteínas por técnicas cromatográficas (líquidos, gases, etcétera) o electroforéticas (2D-PAGE); 2) digerir las proteínas; 3) detectar los fragmentos peptídicos (de proteínas) por espectrometría de masas, y 4) identificar las proteínas.
La aplicación de la proteómica a la clínica se encuentra en etapas tempranas; sin embargo, actualmente se utiliza para: a) identificación de proteínas en una muestra biológica; b) identificación de un perfil de proteínas comparando muestras entre casos y controles; c) determinar la interacción entre diversas proteínas y su red funcional, y d) identificar las modificaciones post-transcripcionales (Mishra, 2010). De esta forma, se lograrán encontrar biomarcadores (proteínas) que sirvan para diagnosticar enfermedades, con el fin de dar un tratamiento más adecuado en un futuro.
Imagen: OpenClipart-Vectors. El gran esfuerzo de muchos científicos ha logrado crear el Proyecto del Proteoma Humano, que proporciona una lista de proteínas que se han encontrado en diferentes tipos celulares y órganos de adultos o de fetos. Estos datos son públicos y reporta más de 30 000 proteínas identificadas en el humano (Omenn et al., 2015).
El uso de la proteómica lo podemos ver en diferentes enfermedades como son: cáncer, diabetes, obesidad, entre otras. Por ejemplo, dentro del ámbito de la reproducción asistida, la proteómica ha sido de gran interés para analizar los gametos (óvulos y espermatozoides) e identificar proteínas que puedan ser utilizados como biomarcadores para poder seleccionar aquellos gametos que aseguren una mejor fertilización y aumentar la tasa de éxito de la reproducción asistida (Kosteria et al., 2017).
Metabolómica
Los metabolitos son aquellas moléculas que participan como sustratos, intermediarios o productos en las reacciones químicas del metabolismo. La metabolómica se define como una tecnología para determinar los cambios globales en la concentración de los metabolitos presentes en un fluido, tejido u organismo en respuesta a una variación genética, a un estímulo fisiológico o patológico (Park, Sadanala y Kim, 2015). La metabolómica nos permite analizar el perfil metabólico de una muestra, de forma cuantitativa y cualitativa. La metodología utilizada es la misma que la descrita en proteómica, en la que se pueden encontrar metabolitos específicos relacionados con el desarrollo de una enfermedad o con la respuesta a un tratamiento nutricio o farmacológico.Recientemente, se ha logrado avanzar de forma importante en el conocimiento de la metabolómica de la obesidad y la diabetes, al asociar la concentración de ciertos metabolitos en suero y orina con un mayor riesgo de desarrollar dichas enfermedades. Estos metabolitos incluyen a varios aminoácidos, lípidos, hidratos de carbono y ácidos nucleicos.
En condiciones de obesidad, la concentración circulante de algunos aminoácidos, especialmente los de cadena ramificada (isoleucina, leucina y valina), está elevada (Chevalier et al., 2005). En población infantil mexicana se logró asociar un perfil de aminoácidos (mayor concentración de arginina, leucina/isoleucina, fenilalanina, tirosina, valina y prolina) con obesidad, con lo cual se tiene la capacidad de predecir un mayor riesgo de hipertrigliceridemia en los siguientes dos años (Moran-Ramos et al. 2017).
Por otro lado, la obesidad se caracteriza por la presencia elevada de ácidos grasos libres en suero. De hecho, se ha visto que la concentración de ácido oleico, palmítico, palmitoleico y esteárico es elevada, mientras que la concentración de etanolamina y lisofosfatidiletanolamina se encuentra disminuida en organismos obesos (Moore et al., 2014). Aunados a los ácidos palmítico, palmitoleico y esteárico, las ceramidas y el diacilglicerol son metabolitos que se encuentran aumentados en pacientes diabéticos (Fiehn et al., 2010). En lo que se refiere a los hidratos de carbono, se ha observado que los pacientes con obesidad y diabetes tienen concentraciones aumentadas de glucosa, fructosa y glicerol en suero (Fiehn et al., 2010; Moore et al., 2014).
|
Anteriormente, se pensaba que el ADN era una estructura simple y lineal. Sin embargo, en las últimas décadas se ha demostrado que el ADN puede plegarse formando estructuras tridimensionales que pueden regular regiones muy lejanas. | |
|
||
Epigenómica
Anteriormente, se pensaba que el ADN era una estructura simple y lineal. Sin embargo, en las últimas décadas se ha demostrado que el ADN puede plegarse formando estructuras tridimensionales que pueden regular regiones muy lejanas. La secuencia de nucleótidos, entonces, no es lo único que regula la expresión génica, sino el enrollamiento del ADN y su posicionamiento durante la formación de estructuras complejas que construyen a los cromosomas.La epigenética se refiere al conjunto de procesos por medio de los cuales se regula la transcripción de los genes sin afectar la secuencia del ADN. Los mecanismos principales por los que se llevan a cabo estas regulaciones del genoma son la adición de grupos metilo (metilación) de los nucleótidos del ADN y la metilación o adición de grupos acetilo (acetilación) de las histonas (proteínas sobre las cuales se enrolla el ADN durante la formación de los cromosomas) (Burdge y Lillycrop, 2014; Desai, Jellyman y Ross, 2015). La epigenómica representa a los cambios epigenéticos globales en una muestra, en un momento dado y en condiciones fisiopatológicas específicas. Por ejemplo, un estudio reveló que la piel que ha sido expuesta al sol sin protección tiene, en su ADN, menos grupos metilos que la piel que ha sido protegida del sol (Vandiver et al., 2015). Los mismos patrones con menor cantidad de grupos metilo se han reconocido para las células cancerosas en comparación con las células sanas. Así, la epigenómica de la exposición al sol y de la progresión del cáncer son similares; esta similitud puede ser la respuesta molecular de cómo el cáncer de piel se asocia a la exposición al sol sin protección.
Las técnicas por medio de las cuales se estudia el epigenoma son muy diversas. En primer lugar, para conocer los patrones de metilación en el ADN, se utiliza frecuentemente la “secuenciación con bisulfito”. También, se pueden emplear anticuerpos que se unan específicamente a los nucleótidos metilados para su reconocimiento (Han y He, 2016). En segundo lugar y para el caso de la modificación (metilación o acetilación) de histonas, se puede precipitar la cromatina utilizando anticuerpos que se unan específicamente a las histonas.

Imagen: GDJ. Un ejemplo muy interesante de la aplicación de la epigenómica a la clínica es la llamada programación fetal. Esta trata del destino metabólico de los hijos que han sido expuestos a ciertas condiciones nutricias durante el desarrollo en el útero. Las investigaciones del caso de la hambruna holandesa de 1944 nos permitieron ver que los niños nacidos de madres desnutridas tenían mayor tendencia a la obesidad y enfermedades metabólicas en la vida adulta (Ravelli, Stein y Susser, 1976). Ahora sabemos que tanto la desnutrición como la obesidad de la madre en la etapa fetal influyen sobre la salud metabólica del niño, del adolescente y del adulto más adelante en la vida (Reichetzeder et al., 2016). En diversos estudios se ha concluido que la dieta materna puede regular la transcripción de genes involucrados en la formación de tejido adiposo (adipogénesis), en la producción de lípidos (lipogénesis) y en el metabolismo de la glucosa. Un ejemplo de estos genes es el que codifica para la hormona leptina. La región que regula la transcripción del gen de la leptina tiene mayor número de grupos metilo después de consumir una dieta rica en grasas. Esta metilación incrementada provoca la disminución de la expresión del gen de leptina y, como consecuencia, existe menor concentración de esta hormona en suero (Milagro et al., 2009) Debido a que la acción de la leptina es favorecer la saciedad, su menor concentración promueve mayor consumo de alimento y contribuye a la formación de tejido adiposo y como consecuencia, la obesidad.
Nutrigenómica y nutrigenética
La nutrigenómica es la herramienta que nos deja conocer, de manera global, los cambios en la expresión de genes en respuesta al consumo de un nutrimento, alimento o dieta. Por ejemplo, se sabe que el consumo de ácidos grasos poliinsaturados (AGPI) resulta en un beneficio para la salud cardiovascular. En un estudio se determinó la influencia del AGPI docosahexanoico y sus metabolitos sobre la expresión global de genes y se concluyó que los genes que participan en la formación de la placa de ateroma que bloquea las arterias se encuentra disminuida (Merched et al., 2008). A partir de este tipo de trabajos, se ha visto que la dieta participa en los cambios de expresión de genes y que modifica el metabolismo.Por otra parte, la nutrigenética se encarga de estudiar los efectos que tiene una variante genética sobre la respuesta del individuo a los nutrimentos. Existen referencias antiguas acerca de la variabilidad interindividual en respuesta a factores dietéticos, como la del poeta y filósofo griego Tito Lucrecio (99 a.C.-55 a.C.), quien citó: “Lo que para unos es comida, es amargo veneno para otros”.
La profundización en el estudio de las enfermedades asociadas a las variantes genéticas ha generado un mejor entendimiento de la influencia de los nutrimentos y de la dieta sobre el estado de salud y enfermedad de los humanos. Un ejemplo clínico es la fenilcetonuria, la cual representa un error innato del metabolismo dado por la presencia de mutaciones en el gen que codifica para la enzima hidroxilasa de la fenilalanina (Neeha y Kinth, 2013). Como consecuencia, esta enzima no es funcional, provocando que el metabolismo de dicho aminoácido se vea afectado y se acumule el fenilpiruvato, un metabolito neurotóxico. Los pacientes con diagnóstico de fenilcetonuria deben consumir una dieta restringida en el aminoácido fenilalanina para evitar el acúmulo del metabolito neurotóxico, el cual provoca retraso mental.
Debido que la nutrigenética se basa en los cambios de variantes presentes en el ADN, los cuales influyen en la manera en que se metabolizan los nutrimentos, las metodologías utilizadas para determinar cuestiones de nutrigenética son las mismas que en genómica. Por otra parte, dado que la nutrigenómica estudia el impacto de los nutrimentos sobre la expresión de genes, las tecnologías utilizadas para su análisis son las mismas que las de la transcriptómica.
Conclusiones
Las “ómicas” representan el análisis de un gran número de moléculas a partir de muestras biológicas, gracias al avance tecnológico que se ha dado en los últimos años y a la formación de equipos multidisciplinarios que ayudan a la interpretación de los datos. La creación de los biobancos ha logrado recaudar un gran número de muestras, las cuales han sido analizadas desde las diferentes “ómicas” (genómica, transcriptómica, proteómica, metabolómica, nutrigenómica, epigenómica, entre otras) para poder obtener nueva información de un fenómeno biológico. Hasta ahora, nos hemos beneficiado de estas ciencias para la creación de biomarcadores que se asocian o predicen un proceso biológico, ya sea normal o que conlleva a una enfermedad.Se ha logrado estudiar cada “ómica” por separado, pero el reto será interrelacionar a todas estas disciplinas. De esta forma, el estudio de las “ómicas” permitirá entender la red de moléculas y de procesos biológicos que estén involucrados en un proceso biológico o en una enfermedad. Cuando esto suceda, podremos utilizar la información para el oportuno diagnóstico de una enfermedad, para la generación de medicamentos más específicos y para la creación de la medicina personalizada, la cual busca individualizar la atención de los pacientes por medio de la predicción, prevención y tratamiento de las enfermedades, con el conocimiento de los antecedentes genéticos, la exposición ambiental y la alimentación de cada individuo.
En un futuro, los sistemas de salud podrán utilizar la información obtenida a partir de las “ómicas” para tratar los padecimientos más frecuentes de una población utilizando la medicina personalizada. Al mismo tiempo, se debe de contemplar que los datos generados por las “ómicas” deberán de respetar los aspectos éticos y legales establecidos por la legislación, con el fin de proteger el anonimato de los individuos. Por esta razón, se ha publicado recientemente una revisión del estatus de las regulaciones de los biobancos en México (Motta-Murguia y Saruwatari-Zavala, 2016).
1 Para mayor información, revisar la página http://omics.org.
Bibliografía
Avery, O. T., MacLeod, C. M., y McCarty, M. (1944). Studies on the chemical nature of the substance inducingtransformation of pneumococcal types. Journal of Experimental Medicine, 79(2), 137–158. DOI: <http://doi.org/10.1084/jem.79.2.137>.
Bargalló-Rocha, J. E. et al. (2015). Cost-Effectiveness of the 21-Gene Breast Cancer Assay in Mexico. Advances in Therapy, 32(3), 239–253. DOI: <http://doi.org/10.1007/s12325-015-0190-8>.
Begum, F., Ghosh, D., Tseng, G. C. y Feingold, E. (2012). Comprehensive literature review and statistical considerations for GWAS meta-analysis. Nucleic Acids Research, 40(9), 3777–3784. DOI: <http://doi.org/10.1093/nar/gkr1255>.
Burdge, G. C. y Lillycrop, K. A. (2014). Environment-physiology, diet quality and energy balance: the influence of early life nutrition on future energy balance. Physiology y Behavior. DOI: <http://doi.org/10.1016/j.physbeh.2013.12.007>.
Chevalier, S., Marliss, Morais, Lamarche y Gougeon (2005). Whole-body protein anabolic response is resistant to the action of insulin in obese women. American Journal of Clinical Nutrition, 82(2), 355–365. DOI: <https://www.ncbi.nlm.nih.gov/pubmed>.
Corvol, H. et al. (2016). Translating the genetics of cystic fibrosis to personalized medicine. Translational Research. DOI: <http://doi.org/10.1016/j.trsl.2015.04.008>.
Desai, M., Jellyman, J. K. y Ross, M. G. (2015). Epigenomics, gestational programming and risk of metabolic syndrome. International Journal of Obesity. DOI: <http://doi.org/10.1038/ijo.2015.13>.
Fiehn, O., Timothy Garvey, W., Newman, J. W., Lok, K. H., Hoppel, C. L. y Adams, S. H. (2010). Plasma metabolomic profiles reflective of glucose homeostasis in non-diabetic and type 2 diabetic obese African-American women. PLoS ONE, 5(12), 1–10. DOI: <http://doi.org/10.1371/journal.pone.0015234>.
Gutierrez Aguilar, R., Kim, D. H., Woods, S. C. y Seeley, R. J. (2011). Expression of New Loci Associated With Obesity in Diet-Induced Obese Rats: From Genetics to Physiology. Obesity (Silver Spring). DOI: <https://doi.org/10.1038/oby.2011.236>.
Han, Y. y He, X. (2016). Integrating epigenomics into the understanding of biomedical insight. Bioinformatics and Biology Insights. Recuperado de: <https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5138066/>.
Harrow, J. et al. (2012). GENCODE: The reference human genome annotation for the ENCODE project. Genome Research, 22(9), 1760–1774. DOI: <http://doi.org/10.1101/gr.135350.111>.
Hershey, A. D. y Chase, M. (1952). Independent functions of viral protein and nucleic acid in growth of bacteriophage. Journal of General Physiology, 36(1), 39–56. Reciperado de: <https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2147348/>.
International Human Genome Sequencing Consortium. (2004). International Human Genome Sequencing Consortium. Finishing the euchromatic sequence of the human genome. Nature, 431, 931–945. Recuperado de: <http://www.nature.com/nature/journal/v431/n7011/full/nature03001.html?foxtrotcallback=true>.
Kosteria, I. et al. (2017). The use of proteomics in assisted reproduction. In Vivo, 31(3), 267–283. DOI: <http://doi.org/10.21873/invivo.11056>.
LaFramboise, T. (2009). Single nucleotide polymorphism arrays: A decade of biological, computational and technological advances. Nucleic Acids Research. DOI: <http://doi.org/10.1093/nar/gkp552>.
Manolio, T. A. (2010). Genomewide Association Studies and Assessment of the Risk of Disease. The New England Journal of Medicine, 363(2), 166–176. DOI: <http://doi.org/10.1056/NEJMra0905980>.
Merched, A. J. et al. (2008). Atherosclerosis: evidence for impairment of resolution of vascular inflammation governed by specific lipid mediators. The FASEB Journal, 22(10), 3595–3606. DOI: <http://doi.org/10.1096/fj.08-112201>.
Milagro, F. I. et al. (2009). High fat diet-induced obesity modifies the methylation pattern of leptin promoter in rats. Journal of Physiology and Biochemistry, 65(1), 1-9. Rrecuperado de: <http://www.ncbi.nlm.nih.gov/pubmed/19588726>.
Mishra, N. (2010). Introduction to Proteomics: Principles and Applications. Introduction to Proteomics: Principles and Applications. DOI: <http://doi.org/10.1002/9780470603871>.
Moore, S. C. et al. (2014). Human metabolic correlates of body mass index. Metabolomics, 10(2), 259–269. DOI: <http://doi.org/10.1007/s11306-013-0574-1>.
Moran-Ramos, S. et al. (2017). An amino acid signature associated with obesity predicts 2-year risk of hypertriglyceridemia in school-age children. Scientific Reports. Recuperado de: <https://www.nature.com/articles/s41598-017-05765-4>.
Motta Murguia, L. y Saruwatari-Zavala, G. (2016). Mexican Regulation of Biobanks. The Journal of Law, Medicine y Ethics : A Journal of the American Society of Law, Medicine y Ethics, 44(1), 58–67. Recuperado de: <https://www.ncbi.nlm.nih.gov/pubmed/27256124>.
Neeha, V. S. y Kinth, P. (2013). Nutrigenomics research: A review. Journal of Food Science and Technology, 50(3), 415–428. DOI: <http://doi.org/10.1007/s13197-012-0775-z>.
Omenn, G. S. et al. (2015). Metrics for the human proteome project 2015: Progress on the human proteome and guidelines for high-confidence protein identification. Journal of Proteome Research, 14(9), 3452–3460. DOI: <http://doi.org/10.1021/acs.jproteome.5b00499>.
Park, S., Sadanala, K. C. y Kim, E.-K. (2015). A Metabolomic Approach to Understanding the Metabolic Link between Obesity and Diabetes. Molecules and Cells. DOI: <http://doi.org/10.14348/molcells.2015.0126>.
Ravelli, G. P., Stein, Z. A. y Susser, M. W. (1976). Obesity in Young Men after Famine Exposure in Utero and Early Infancy. New England Journal of Medicine, 295(7), 349–353. DOI: <http://doi.org/10.1056/NEJM197608122950701>.
Reichetzeder, C. et al. (2016). Developmental Origins of Disease – Crisis Precipitates Change. Cellular Physiology and Biochemistry, 39(3), 919–938. DOI: <http://doi.org/10.1159/000447801>.
Vandiver, A. R., Irizarry, R. Hansen, K, Garza, L., Runarsson, A., Li, X., Chien, A., Wang, T., Leung, S. Kang, S y Feinberg, A. (2015). Age and sun exposure-related widespread genomic blocks of hypomethylation in nonmalignant skin. Genome Biology. DOI: <https://doi.org/10.1186/s13059-015-0644-y>.
Venter, J. C. et al. (2001). The sequence of the human genome. Science, 291(5507), 1304–1351. DOI: <http://doi.org/10.1126/science.1058040>.
Watson, J. D. y Crick, F. H. C. (1953). Molecular structure of nucleic acids. Nature. DOI: <http://doi.org/10.1097/BLO.0b013e3181468780>.
COMENTARIOS